前言
参考来自Dr. Changkun Ou写的现代C++学习,学完这个去看modern c++的项目达到巩固作用。
chap1 语言可用性的强化
在我们声明或者定义一个变量常量的时候,都是发生在程序运行之前,这些行为可能发送在编写代码和编译器编译时候的行为。而语言可用性,即运行时之前发送的语言行为
常量
nullptr
nullptr是为了代替NULL而出现的,*这是因为C++不允许void 隐式转换成其他类型**。
而NULL有部分编译器会把他定义成(void*)0,所以下面的代码就会出错
char* s=NULL;哪怕NULL=0这种定义,也会出错,比如
void foo(char*);
void foo(int);foo(NULL)回去调用第二个foo,非常反直觉。为此,C++11引入了nullptr,专门区分空指针和0;
#include <type_traits>
if (std::is_same<decltype(NULL), decltype(0)>::value) {
std::cout << "1" << std::endl;
}
if (std::is_same<decltype(NULL), decltype((void*)0)>::value) {
std::cout << "2" << std::endl;
}
if (std::is_same<decltype(NULL), decltype(nullptr)>::value) {
std::cout << "3" << std::endl;
}总之,平时一定要区分nullptr,0,不要用NULL!
一句话,主要就是因为C++的void不能隐式转成char 等其他类型的指针,而NULL定义成0传参的时候遇到函数重载又会有问题,因此用nullptr,可以强转。
constexpr
这个就是表示他是一个在编译期间就可以计算的值,可以用于函数返回值,也可以用于常量变量的声明定义。
可以看到,虽然len1是const,但是数组的len必须是一个常量表达式,而不是常量
==所以一定要区分常量表达式和常量,前者是在编译期间就计算好了,可以把他当成一个字面值常量,后者只是说不能修改==
C++11 提供了 constexpr 让用户显式的声明函数或对象构造函数在编译期会成为常量表达式,这个关键字明确的告诉编译器应该去验证 在编译期就应该是一个常量表达式。
从C++14开始,constexpr函数才可以使用局部变量,简单地循环,分支等。
比如下面的函数其实是可以的
constexpr int fibonacci(const int n){
if(n==1) return 1;
if(n==2) return 1;
return fibonacci(n-1)+fibonacci(n-2);
}但是,要额外注意的是constexpr函数可以在编译时或运行时计算,这取决于给定的参数是否为编译时常量。所以他未必必须需要在编译的时候就计算出来!
值得一提的是,常量表达式函数必须可计算,比如我这样写
constexpr int fibonacci(const int n) {
if (n == 1) return 1;
if (n == 2) return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int nnnn[fibonacci(12)];可以编译,但是如果fabonacci的参数填写的过大,比如

变量及其初始化
if/switch
C++17以前无法在if和switch语句中声明一个临时变量
比如if(auto a=IsOk())
但是C++17以后是可以的
初始化列表
C++对于没有构造函数的结构,可以使用初始化列表进行初始化,即{};
比如C++的原生数组.int a[]={1,2,3,4};
而对于类对象的初始化,需要通过拷贝构造,也就是需要使用
class1 c=class1(123),而不能使用class1 c{1,2,3}
而有的东西确实需要列表初始化,为了解决这个问题,C++把列表初始化绑定到了类型上。即std::initializer_list,这样为类对象的初始化和原生数组初始化提供了统一的桥梁,也就是都可以这样初始化。
class MagicFoo {
public:
std::vector<int> vec;
MagicFoo(std::initializer_list<int> list) {
for (const auto& value : list) {
vec.push_back(value);
}
}
};
MagicFoo a = { 1,23,4,5 };结构化绑定
C++17 可以让我们写出这样的代码:
std::tuple<int, std::string, float> get() {
return { 11,"lihua",155.43 };
}
int main() {
const auto [age, name, high] = get();
return 0;
}只要是结构,pair,tuple都可以使用结构化绑定
类型推导
auto
auto最好用的地方就是可以用于迭代器
for(vector<int>::const_iterator it = vec.cbegin(); it != vec.cend(); ++it)可以避免冗余的迭代器类型;
从C++ 20开始(而lambda早在C++14就支持了),auto可以用于传参!
所以就有如下逆天的写法(这种写法可以用于简单的泛型场景)
auto _auto(const auto& __auto)->auto{
return __auto;
}但是目前auto还不能推导数组,即下面的写法是错误i的
auto a1[100]={};decltype
decltype 关键字是为了解决 auto 关键字只能对变量进行类型推导的缺陷而出现的。他和typeof很像,他的用法是
decltype(表达式),比如如下用法
auto x=1;
auto y=2;
decltype(x+y) z;总之你可以理解为decltype(表达式)就是一个类型描述符了!,就像int float一样;
此外,decltype把他当成一个类型描述符,它还可以用于函数的返回值
比如下面
template<typename T,typename U>
decltype(x+y) foo(T x, U y);然而这个是编译不通过的,这是因为x y这个时候是没有被定义!因此C++11引入了一个尾返回类型,利用auto返回将返回类型后置
template<typename T,typename U>
auto foo(T x, U y)->decltype(x+y);而C++ 14开始,可以直接让普通的函数具备返回值推导,因此上述写法变成
template<typename T,typename U>
auto foo(T x, U y);decltype(auto)
看完语言运行强化讲解
控制流
if constexpt
C++11引入了constexpr关键字,如果我们把这一特性引入到条件判断中去,让代码在编译时就完成分支判断, 就可以让程序效率更高
可以写成如下写法
template<typename T>
auto print_type_info(const T& t) {
if constexpr (std::is_integral<T>::value) {
return t + 1;
}
else {
return t + 0.01;
}
}这样实际编译的时候就会出现两个函数…目前没理解这个到底啥意思
总之就是更快了,这个在后面模板形参包有点用,但是不多
区间for-each
就像python一样简单,这个也用得比较多,总之如果你有begin和end函数,并且返回的迭代器可以进行++操作,就可以进行for-each迭代了;
模板
-
外部模板
众所周知,C++模板在编译的时候才会被实例化,换句话就是.cpp编译遇到了完整定义的模板,都会实例化,而C++11引入了外部模板,强制实例化的位置
extern template class std::vector<double>;-
类型别名模板
模板是用来产生类型的。,C++可以使用typedef等给一个类型定义一个新名词,
但是没办法为模板定义一个新的名称,因为模板不是类型!
而C++11引入了using,不仅和传统的typedef一样,还可以给模板定义别名
template <typename T>
class TTT{
public:
T a;
}
template<typename T>
using MyTTT=TTT;
MyTTT<double> a;-
变长模板参数(模板形参包)
C++11新增了允许任意个数,任意类型的模板参数,不需要再定义的时候就把个数固定!
语法是
template<typename... Ts> class Magic;比如下面的定义
class Magic<int,char,std::vector<char>>;如果你不希望生成类似Magic<>这种的,那么可以写一个固定的
比如
template<typename Must,typename... Args>
class Magic{
}在模板中使用typename...表示不定长模板参数之外,还可以在函数参数使用同样的方法表示
template<typename... Args>
void printf(const std::string &str,Args... args){
}Args...这个就表示不定长参数的类型,把他当成一个类型就行;
如何解包呢?其实也很简单,解包也有相关不定长参数对应的函数,比如
template<typename... Args>
void printff(const std::string& str, Args... args) {
std::cout << sizeof...(args) << std::endl;
}printff("lala", 1, 2, 22.222, "wocao");上面只是简单地处理模板形参包,目前还没有一种对参数进行解包的好办法,两种经典处理方法分别是递归和变参模板展开
- 递归处理
递归处理1
template<typename T0>
void printfff(T0 t) {
std::cout << t << std::endl;
}
template<typename T, typename... Args>
void printfff(T a1, Args... args) {
std::cout << a1;
printfff(args...);
}递归处理2
void printfff(void) {
}
template<typename T, typename... Args>
void printfff(T a1, Args... args) {
std::cout << a1 << std::endl;
if (sizeof...(args) == 0) std::cout << "0000" << std::endl;
printfff(args...);//如果arg...长度是0,就会调用printff( void)
}递归处理有一个非常大的弊端,那就是必须加一个printfff()只有一个参数的情况,这是因为当模板递归到只有一个参数,这个时候args…是0,编译器会找一个没有参数的printfff,但是这个是不存在的,因此需要定义一个额外的函数,这就是递归处理2
而递归处理1,则是写一个只有一个参数的函数,当只有一个参数的时候,就会调用这个参数,也不会出现找不到的情况,这就是递归处理1
但是无论如何,递归都需要声明和定义一个结束函数,非常不方便
- 变参模板展开
因此C++17引入了一种模板变参数展开,其实就是(xx…),这样就相当于展开了,你就可以把他理解为展开成多个参数,然后填写进去.
可以简写成以下形式
template<typename T0, typename... T>
void printf2(T0 t0, T... t) {
std::cout << t0 << std::endl;
if constexpr (sizeof...(t) > 0) printf2(t...);
}注意,一定要if constexpr,这样编译期间就可以避免刚才找不到函数的问题,其实本质上就是生成了两个函数!
这里可能会对...这个运算符表示疑惑,这个运算符通常用于下述场景
- 函数参数展开:用于函数模板中,展开函数的参数列表。
- 折叠表达式:在C++17中引入,用于简化参数包的展开,比如在算术运算、逻辑运算中。
当使用...展开函数参数包时,...放在参数包的名称之后。这种用法主要用于函数模板中,允许函数接受可变数量的参数。
上面的那些Args... args,args...其实都是模板参数展开!这是C++老的语法,而新的语法则是折叠表达式
- 折叠表达式
c++17中给变长参数性质进一步带给表达式
下面例子
template<typename... Args>
auto sum(Args... args) {
return (args + ...);
}或者这样写
template<typename... Args>
void print(Args... args) {
(std::cout << ... << args) << std::endl;
}
让我们再来理解一下模板形参包
我们可以这样理解,我们要理解模板生成类型,因此template<typename... Args>
这是一个模板参数包的声明,当你使用 typename... Args,你告诉编译器这个模板可以接受任意数量(包括零个)的类型参数。这些类型参数可以在模板的定义中使用。
Args... args这是一个函数参数包的声明。在这个上下文中,Args... 表示这是一个由之前声明的模板参数包 Args 中的类型组成的函数参数包。args 是这个函数参数包的名字,它代表了传递给函数的实际参数集合。
例如,如果调用 print(1, "hello", 2.5):
Args将被推断为int, const char*, double。args将是一个实际参数的列表,包含值 1 (int), “hello” (const char*), 和 2.5 (double)。接着来看折叠表达式在C++17中引入的折叠表达式允许对参数包进行更复杂的操作。在折叠表达式中,...的位置取决于所执行的操作类型。- 二元左折叠:
...放在操作符和参数包之间。- 形式:
(init op ... op pack) - 例子:
(... + args)(对于args中的每个元素,加到一个初始值上)
- 形式:
- 二元右折叠:
...放在参数包和操作符之间。- 形式:
(pack op ... op init) - 例子:
(args + ...)(对于args中的每个元素,加到一个初始值上)
- 形式:
- 一元左折叠:
...放在操作符之前。- 形式:
(... op pack) - 例子:
(... && args)(检查args中的每个元素是否都为真)
- 形式:
- 一元右折叠:
...放在操作符之后。- 形式:
(pack op ...) - 例子:
(args && ...)(检查args中的每个元素是否都为真)
- 形式:
面向对象
委托构造
C++11 引入了委托构造的概念,这使得构造函数可以在同一个类中一个构造函数调用另一个构造函 数,从而达到简化代码的目的:
那么以前写的代码,构造函数其实很多都写错了!直接委托一下就行。
class base{
int a;
int b;
base(){a=1;}
base(int _b):base(){
b=_b;
}
}唯一需要注意的是,委托构造,不能再用列表初始化初始其他成员了,所以b=_b必须放在函数体中。
显示禁用默认函数
其实就是xx=delete;有时候不能有拷贝构造,移动语义啥的,所以必须有个优雅地删除
强类型枚举
这个问题是因为C++,枚举类型不安全,可能会被置为整数 ,因此C++11引入了强类型枚举,使用enum class的语法,这样就不可以传递整数,而必须传递枚举了,他不可以被隐式地转换成整数。
chap1 总结
比较重要的是
- auto/decltype推导返回值,表达式类型,
- for循环的升级,if switch可以声明变量,多用结构化绑定有大好处!
- 列表初始化如何在原生和C++的容器打通桥梁,
- 还有变参模板和模板形参包
chap02 运行时增强
lambda
参数捕获
lambda表达式是现代C++最重要的特性,而lambda本身其实就是匿名函数,一般是一个在需要函数,但是不想费力去命名函数的场景去使用
lambda语法表示是
[捕获列表] (参数列表) mutable 异常属性 -> retType{函数体}
这个捕获&是引用捕获,而不加&则是值捕获
• [] 空捕获列表
• [name1, name2, . . . ] 捕获一系列变量
• [&] 引用捕获, 让编译器自行推导引用列表
• [=] 值捕获, 让编译器自行推导值捕获列表
- 表达式捕获
C++14新增了表达式捕获,考虑如下代码
void lambdaExpCapture() {
auto imp = std::make_unique<int>(1);
auto add = [v1 = 1, v2 = std::move(imp)](int x, int y){
return x + y + *v2;
};
std::cout << add(3, 4) << std::endl;
}在上面的代码中,important 是一个独占指针,是不能够被 “=” 值捕获到,这时候我们可以将其转移为右值,在表达式中初始化。
- 泛型lambda
其实就是使用auto关键字给参数使用(auto关键词 C++ 20才可以给普通的函数使用,但是C++14开始,就可以给lambda使用了!)
这就是lambda的泛型,比如下面代码:
auto add=[](auto x,auto y)->auto{
return x+y;
}函数包装器
其实就是可调用对象的拓展
std::function
在 C++11 中,统一了这些概念,将能够被调用的对象的类型, 统一称之为可调用类型。而这种类型,便是通过 std::function 引入的。
C++11 std::function 是一种通用、多态的函数封装, 它的实例可以对任何可以调用的目标实体进行存储、复制和调用操作, 它也是对 C++ 中现有的可调用实体的一种类型安全的包裹
#include <functional>
#include <iostream>
int foo(int para){
return para;
}
int main(){
std::function<int(int)> func = foo;
int imp = 10;
std::function<int(int)> func2 = [&](int v)->int {
return v + imp;
};
std::cout << func(10) << std::endl;
std::cout << func2(10) << std::endl;
}std::bind&std::placeholder
bind的作用就是给参数占位, 它解决的需求是我们有时候可能并不一定能够一次性获得调用某个函数的全部参数,通过这个函数, 我们可以将部分调用参数提前绑定到函数身上成为一个新的对象,然后在参数齐全后,完成调用。
int foo(int a,int b,int c){
return a+b+c;
}
int main(){
//std::placerholder1代表对参数1进行占位
auto bind_arg_1=std::bind(foo,std::placeholders::_1,1,2);
std::cout<<bind_arg_1(1)<<std::endl;
}或者我想占位第二个参数
//std::placerholder1代表对参数1进行占位
auto bind_arg_1 = std::bind(foo1, std::placeholders::_2,1, 5);
std::cout << bind_arg_1(0,1,4) << std::endl;那么0,4都是占位的,并不会真正的被填进去,而且4不写也可以,反而感觉不太方便。
右值引用
各种值的分类
- 左值
顾名思义,运算符左边的值,左值是指这个表达式过后仍然持久存在的对象
- 右值
==实际上,C++的值类型(Value category)和类型(Type)是两个概念==
类型,就三种
- T
- T&
- T&&
而值类型,很多种,C++11引入了新的纯右值、将亡值的概念。也就是即将销毁,但是可以移动的值,其实是为了配合C++的移动语义
比如下面的代码
- 左值(lvalue):表示具有持久对象身份,可以取地址的表达式。
- 将亡值(xvalue):表示即将被销毁的对象,通常是可以被移动的对象。
- 纯右值(prvalue):表示纯粹的值,没有对象身份,比如字面量、临时对象等。
- 右值(rvalue):包括将亡值和纯右值。
- 泛左值(glvalue):包括左值和将亡值。
纯右值就说那些纯粹的字面量,比如10 true,字面量除了字符串字面量之外,都是纯右值
数组可以隐式转换成对应的指针类型,转换的结果一定是一个右值,所以可以被右值引用,因此字面常量字符串,可以被左值引用,也可以被右值引用,也可以不引用!非常灵活
const char* p = "01234"; // 正确,"01234" 被隐式转换为 const char*
const char*&& pr = "01234"; // 正确,"01234" 被隐式转换为 const char*,该转换的结果是纯右值std::vector<int> foo(){
return {1,2,3,4,5};
}
int main(){
auto v= foo();
}在传统C++,有一个非常大的性能问题,那就是如果返回的数组很大,这个时候v其实会重新开辟一份内存,v是左值,而foo返回的是纯右值,而将亡值就是一种这种定义,临时值可以被识别,但是同时又可以被移动?
我的理解是foo的返回值可以被识别,如果可以移动,那就是将亡值。而foo的返回值就说如此。
在 C++11 之后,编译器为我们做了一些工作,此处的左值 temp 会被进行此隐式右值转换, 等价于 static_cast<std::vector<int> &&>(temp),进而此处的 v 会将 foo 局部返回的值进行移动。 也就是后面我们将会提到的移动语义。
右值引用和左值引用,如果想拿到一个将亡值,需要使用T&& 这种形式,这样可以让临时对象的声明周期延长。而C++11增加了std::move将左值转换成右值引用,右值引用允许我们区分一个对象是否是临时的(可以安全地”移动”)。
void ref(std::string& str) {
std::cout << "左值引用" << std::endl;
}
void ref(std::string&& str) {
std::cout << "纯右值/将亡值" << std::endl;
}
int main() {
std::string s1 = "aa";
std::string&& die_value = std::move(s1);
const std::string& deley_value = die_value;
ref(s1);/*左值*/
ref(die_value);/*左值 因为是引用 右值引用 不属于纯右值和将亡值*/
ref(std::move(s1));/*将亡值*/
ref("llaa");/*将亡值*/
}移动语义
有了前面相关的知识,传统的C++拷贝构造是深拷贝,这一点非常反人类,因为如果返回的是一个临时对象(将亡值),那么接收他的新对象就必须也得构造一次!这个资源就得重新分配。
这种浪费空间和时间的行为直到移动语义的出现解决了
#include <iostream> // std::cout
#include <utility> // std::move
#include <vector> // std::vector
#include <string> // std::string
int main() {
std::string str = "Hello world.";
std::vector<std::string> v;
// 将使用 push_back(const T&), 即产生拷贝行为
v.push_back(str);
// 将输出 "str: Hello world."
std::cout << "str: " << str << std::endl;
// 将使用 push_back(const T&&), 不会出现拷贝行为
// 而整个字符串会被移动到 vector 中,所以有时候 std::move 会用来减少拷贝出现的开销
// 这步操作后, str 中的值会变为空
v.push_back(std::move(str));
// 将输出 "str: "
std::cout << "str: " << str << std::endl;
return 0;
}比如这个代码,str操作之后会变空!
在实现容器的时候,除了类本身需要有移动语义,容器本身,比如有push_xx,也要有相关的接受auto&& 的参数
ref collapsing
而对于l这个变量,他是一个左值,但是可以可以被传递为int &&的,这是因为C++引用坍缩的规则
引用折叠规则适用于引用的引用类型,当我们有一个引用指向另一个引用时,需要确定最终的引用类型。
规则如下:
T& &、T& &&、T&& &折叠为T&。T&& &&折叠为T&&。
折叠引用只涉及引用的引用,static_cast等强制转换是不会有ref collapsing的。
折叠引用只出现在下面几种情况
- 完美转发
template <typename T>
void process(T&& t);
int x = 10;
process(x); // 传入左值
process(20); // 传入右值传入左值x,推导得到的t是T&,
传入20这个将往值,其实他的类型是T&& ,可以变成T&&
这个机制允许 process 函数同时接受左值和右值,并保持其值类别。
- auto类型推导
int x = 42;
int& ref = x;
auto a = x; // a 的类型为 int,引用被忽略
auto b = ref; // b 的类型为 int,引用被忽略
auto& c = x; // c 的类型为 int&
auto&& d = x; // d 的类型为 int&,引用折叠:`int& &&` 折叠为 `int&`
auto&& e = 5; // e 的类型为 int&&auto&& 是一种通用引用(万能引用),能够根据初始值的值类别,推导出相应的引用类型。
这里可能会疑惑的是,但是C++标准规定了
使用 auto 进行类型推导时,C++ 标准规定:
- 对于非函数模板:
auto忽略顶层引用,即变量的类型是int&、int&&,初始值是int。auto&或auto&&可以保留引用特性。
- 特殊的类型推导规则(涉及到万能引用):当使用
auto&&时,它可以被视为一种 万能引用(Universal Reference),其类型推导规则类似于模板参数的推导。 auto&&类型推导:- 如果初始值是左值,则
auto被推导为 左值引用类型T&。 - 如果初始值是右值,则
auto被推导为 值类型T。
- 如果初始值是左值,则
- decltype
int x = 0;
int& ref = x;
decltype(x) a; // a 的类型为 int
decltype(ref) b = x; // b 的类型为 int&
decltype((x)) c = x; // c 的类型为 int&,注意是双层括号
decltype((ref)) d = x; // d 的类型为 int&
int&& rval = 5;
decltype(rval) e = 5; // e 的类型为 int&&
decltype((rval)) f = x;// f 的类型为 int&,引用折叠:`int&& &` 折叠为 `int&`- 类型别名(using、typedef)
完美转发
#include <utility>
template <typename T, typename... Args>
std::unique_ptr<T> make_unique(Args&&... args) {
return std::unique_ptr<T>(new T(std::forward<Args>(args)...));
}- 使用转发引用和引用折叠,
make_unique能够完美地转发参数,无论是左值还是右值。
std::move vs std::forward
如果我们看stl中 std::move和std::forward的实现,会发现他们有很大不同
template <class T>
struct remove_reference
{
typedef T type;
};
template <class T>
struct remove_reference<T &>
{
typedef T type;
};
template <class T>
struct remove_reference<T &&>
{
typedef T type;
};
template<typename T>
typename remove_reference<T>::type&& move(T&& arg) noexcept {
return static_cast<typename remove_reference<T>::type&&>(arg);
}为什么要这样呢,不妨考虑下自己实现一个std::move
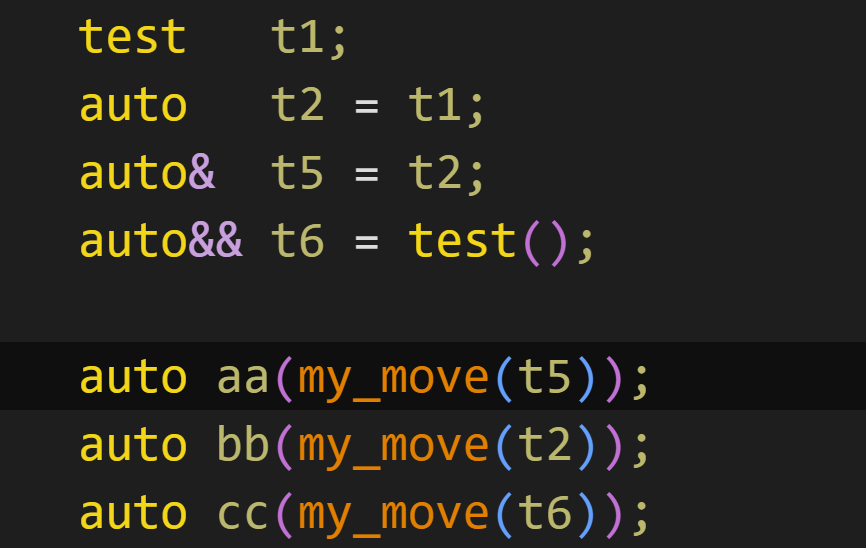
template <typename T>
constexpr T&& mymove(T&& val){ return static_cast<T&&>(val); }那么我们实现的这个简单的move会发生什么呢

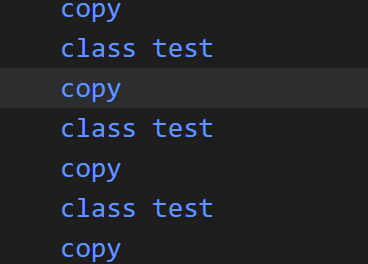
非常反直觉,全是拷贝构造,一个移动构造都没有,这是为什么呢?
在此之前,需要恶补一个概念
- 基本类型匹配
template <typename T>
void func(T param);
int x = 0;
func(x); // T 被推导为 int,param 类型为 int- 涉及指针
template <typename T>
void func(T* param);
int* ptr = &x;
func(ptr); // T 被推导为 int,param 类型为 int*- 左值引用形参
template <typename T>
void func(T& param);
int x = 0;
func(x); // T 被推导为 int,param 类型为 int&- 右值引用形参
template <typename T>
void func(T&& param);
func(x); // x 是左值,T 被推导为 int&,param 类型为 int& &&,引用折叠为 int&
func(5); // 5 是右值,T 被推导为 int,param 类型为 int&&so,this is black magic。c++是这样的,开发者只需要考虑各种形参实参模板推导就行了,但是C++委员会要考虑的就多了。
那么问题回到刚才,就不难理解所有的都调用拷贝构造了,
第一个登场的是t5,他是左值引用,左值,T推导的是T&,T& && 引用坍缩成T&,因此返回T&
第二个是t2,他和t5是一样的
第三个是右值引用t6,但是它属于左值,so,仍然和上面两位是一样的流程。最终全部清一色返回T&!
所以stl的std::move,形参虽然是右值引用,但是无论怎么推导,都可以保证返回的一定是右值引用了。
而他的形参其实是万能引用,保证什么类型都可以传进来。
这里还有个阴霾没有解决,那就是:
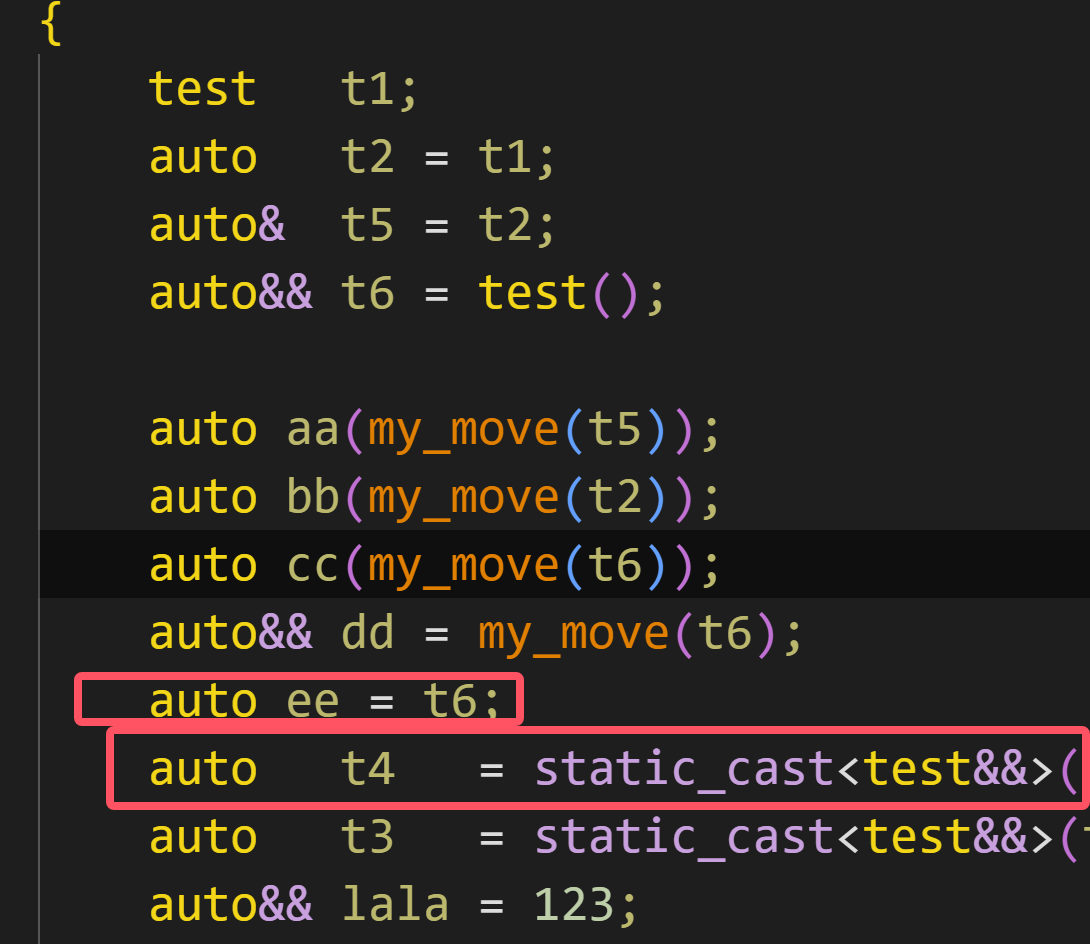
这两个都是右值引用,可是ee调用的是copy,而t4调用的是move,明明他们类型都是一样的,为什么却如此差别呢?
这是因为他们只是类型相同,而值类别不一样!
t6是右值引用,有自己名字,是左值!而static_castxxx的结果其实是一个右值!他没有名字,是一个匿名的临时对象!又是一个black magic!
而std::forward的实现如下,毫无疑问,他也用到了引用折叠和模板参数推导
template <class _Ty>
_NODISCARD constexpr _Ty&& forward(
remove_reference_t<_Ty>& _Arg) noexcept { // forward an lvalue as either an lvalue or an rvalue
return static_cast<_Ty&&>(_Arg);
}可以看到,他的参数是remove_reference_t&,但是返回类型是T&&
这种实现方式确保了:
- 无论传入的是左值还是右值,参数
_Arg都可以绑定。 - 根据
T的不同,返回值类型T&&(可能是左值引用或右值引用)能够正确地转发参数。
首先,remove_reference_t<_Ty>& _Arg保证了一定是U&的形参,也就可以保证,可以绑定到右值(右值可以绑定到 const 左值引用,但这里不是 const,所以仅当右值可绑定到左值引用时才成立);为了能够绑定右值,需要在调用 std::forward 时保证传入的参数是一个左值引用。
而返回类型T&&,
- 引用折叠规则:
- 当
T是U(非引用类型)时,T&&为U&&(右值引用)。 - 当
T是U&(左值引用)时,T&&为U& &&,根据引用折叠规则折叠为U&(左值引用)。 - 当
T是U&&(右值引用)时,T&&为U&& &&,折叠为U&&(右值引用)。
比如常见下面的应用
int x = 0; template <typename T> void func(T&& arg) { other_func(std::forward<T>(arg)); } func(x); // x 是左值 - 当
func里面的T被推成T&(注意,右值引用形参的类型推导逻辑一定要自洽,比如这里T如果是T,那么接受的参数是一个T&&,很明显x是左值,应该形参接受引用)
T&& &坍缩成T&,所以arg是一个T&类型,forward中的参数是T&,返回(T&) &&->T&
转发右值
template <typename T>
void func(T&& arg) {
other_func(std::forward<T>(arg));
}
func(0); // 0 是右值T被推导成T,则返回的是T&&,完美。
一个很重要的点:当你写了两个重载函数,比如
template <typename _T>
void foo1(_T&& t)
{
printf("&&rn");
}
template <typename _T>
void foo1(const _T& t)
{
printf(" no &&rn");
}
那么&&将会匹配所有的非const左右值!
带const的只是为了防止你传递const限定符的!
因为no-const可以隐式转换成const,反过来则只能显示。
and last question,为什么forward需要指定模板参数,不能像move那样推导出来?
原因是,std::forward 的参数类型是 std::remove_reference_t<T>&,这其中的 T 编译器并不知道,需要我们手动指定。
具体而言
- 假设
arg的类型是int&,那么:std::forward<int&>(arg):模板参数T为int&。- 参数类型为
std::remove_reference_t<int&>&,即int&。 std::forward<int>(arg):模板参数T为int。- 参数类型为
std::remove_reference_t<int>&,即int&。 - 可以看到,对于相同的参数类型
int&,不同的模板参数T都匹配。
其实就是一个都匹配问题!编译器猜不出来。所以得显示指定,因为形参类型是一定的,你填啥都可以!
principle:使用forward 先于move
chap3 容器
线性容器
std::array
可以理解为std::array是对于原生数组的眼神
std::array的使用也很简单,只需要指定大小和类型即可
使用 std::array 能够让代码变得更加“现代化”,而且封装了一些操作函数,比如获取数组大小以及检查是否非空,同时还能够友好的使用标准库中的容器算法,比如 std::sort。
无序容器
就是使用std::unordered_map和std::unordered_set,他们的查找更快!
元组
C++11的元组就是std::tuple,元组操作核心的主要是三个函数
std::make_tuple来创建一个元组std::get获取元组的某个位置std::tie元组拆包
元组基本操作
auto get_student(int id) {
if (id == 0) {
return std::make_tuple(3.8, "a", "张三");
}
else if (id == 1) {
return std::make_tuple(3.33, "aa", "lala");
}
else return std::make_tuple(3.3333, "AAAA", "LALALA");
}
int main() {
auto s = get_student(1);
std::cout << std::get<0>(s) << std::endl;
//元组拆包
auto [a, b, c] = s;
std::tie(a, b, c) = s;
}运行期索引
如果你仔细思考一下可能就会发现上面代码的问题,std::get<> 依赖一个编译期的常量,所以下面的方式是不合法的:
int index = 1;
std::get<index>(t);因此可以使用C++17的variant,可以理解为非常安全的C++union
这样就可以自己实现了
这个太难了看着,不想写了
chap 4 智能指针与内存管理
传统C++我们使用new/delete来进行使用资源,经常忘记释放,因此C++11引入了智能智能的概念,通过引用计数来进行管理内存资源,这些包括
std::shared_ptr,std::unique_ptr,std::weak_ptr,头文件在<memory>
shared_ptr
它可以记录多少个ptr指向同一个对象,显示地消除delete
而shared_ptr这个类可以通过get获取原始对象的指针,可以通过use_count获取对象引用次数,可以通过reset()减少引用
void foo(std::shared_ptr<int> i) {
(*i)++;
std::cout << "ref count:" << i.use_count() << std::endl;
}
int main() {
auto p = std::make_shared<int>(123);
foo(p);
std::cout << "ref count:" << p.use_count() << std::endl;
return 0;
}输出是2 和1,如果填写左值引用,那么就是1,1,因此这个地方需要额外注意一下!
unique_ptr
它是独占的指针,防止其他指针和自己共享
而搞笑的是,C++11没有提供make_unique这个函数,原因竟然是忘记了!
但是我们可以自己实现,只要是写好了shared_ptr
template<typename T,typename... Args>
std::unique_ptr<T> make_unique(Args&&... args) {
return std::unique_ptr<T>(new T(std::forward<Args>(args)...));
}首先就说Args&&… args,这个使用std::forward 进行了万能转发
而至于为什么是模板形参包!? 那是因为!!构造函数啊啊啊啊啊啊!!太优雅了,c++;
同时,我们可以使用std::move来进行移动语义的
而这里std::forward<Args>(args)...则用到了参数吧的展开!可以把std::forward理解为static_cast,然后后面加上…,就说形参包展开,然后去调用T(展开)的函数,非常的优雅!
总结一下就是
智能指针这种技术并不新奇,在很多语言中都是一种常见的技术,现代 C++ 将这项技术引进,在一定程度上消除了 new/delete 的滥用,是一种更加成熟的编程范式。
后面这个人还有正则表达式,并发啥的,我感觉对我没有帮助,因此现代C++学这些就够了!剩下的就是看相关项目吧!
chap05 单元测试
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。至于单元的大小或范围,并没有一个明确的标准,单元可以是一个函数、方法、类、功能模块或者子系统。
Google Test的核心就是编写测试用例和使用断言。但是,使用Google Test这样的测试框架相比于直接在main函数中调用测试函数有几个重要优势
其实就是用断言+TEST测试
引入很简单,down下来,是cmake编译的,直接当成库引入即可。
根目录的CMake这样写
cmake_minimum_required(VERSION 3.10)
project(gtest LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 17)
SET(CMAKE_CXX_STANDARD_REQUIRED on)
set(CMAKE_MSVC_RUNTIME_LIBRARY "MultiThreadedDebugDLL")
add_subdirectory(3rd-party/googletest-1.15.2/)
add_subdirectory(src/)set(CMAKE_MSVC_RUNTIME_LIBRARY "MultiThreadedDebugDLL")这一句需要指定使用MTd编译,不然会有冲突。
cmake_minimum_required(VERSION 3.10)
project(main LANGUAGES CXX)
set(SOURCES main.cpp)
add_executable(main ${SOURCES})
target_link_libraries(main PRIVATE gtest_main)
target_include_directories(main PRIVATE ${CMAKE_SOURCE_DIR}/3rd-party/googletest-1.15.2/googletest/include)
# add_subdirectory(external)
# target_link_libraries(main PRIVATE external)然后就可以在main.cpp写测试了
#include <iostream>
#include <gtest/gtest.h>
int add(int a,int b){
return a+b;
}
TEST(alogrithm_test ,add_test){
EXPECT_EQ(add(1,2),3);
EXPECT_EQ(add(1,3),4);
EXPECT_EQ(add(1,8),9);
//EXPECT_EQ(add(1,9),3); error
EXPECT_EQ(add(1,10),11);
EXPECT_EQ(add(1,11),12);
EXPECT_EQ(add(1,12),13);
}
int main(int agrc,char** argv){
::testing::InitGoogleTest(&agrc,argv);
return RUN_ALL_TESTS();
}命令行窗口的输出如下
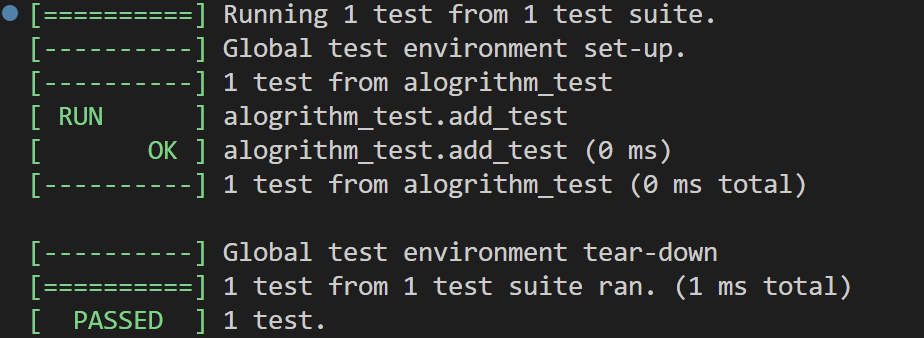
如果失败,则打印函数和行数
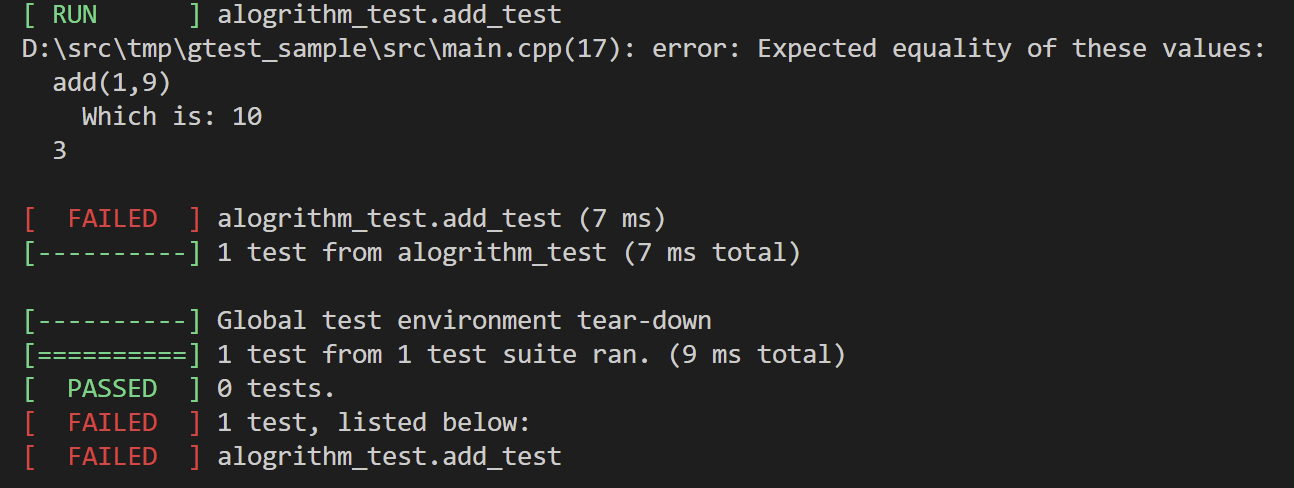
其实单元测试无非就是各种断言啥的,
TEST这个宏两个参数
TEST(TestSuiteName, TestName) {
EXPECT_EQ(1, 1);
}main函数固定写,即可调用所有TestSuite中的Test了。
chap06 modern stl
目前打算写一个完全基于现代C++的仿照stl实现,但是可以用在内核,唯一和stl区别的是不抛出异常。
还有些区别可能是自己实现的成员函数更少,但是无论如何尽量仿照,在学会现代C++ stl的同时,写一个现代C++的stl。
string-√
提到stl,最绕不开的就是string了,因此我这里第一个实现了string/wstring。
实现起来不算难,在实现这个过程中,我主要记录下自己的感悟:
- string有自己的指针(当然stl有优化,如果大小小于8char,那么会存在string本身,不会申请内存)
- string本身的指针里面的内容可以不是以�结尾的,但是调用了
c_str和data之后,我一般会在length后面手动加上0,即_m_data[_m_length] = 0 - stl的所有容器,都有分配器

这个属于基础知识了,这样可以比较灵活地选择何种方式分配内存,这个_Alloc的实现一般是约定成俗的,这里我这个default_allocator实现如下:
首先,模板特化下,只剩一个模板参数:

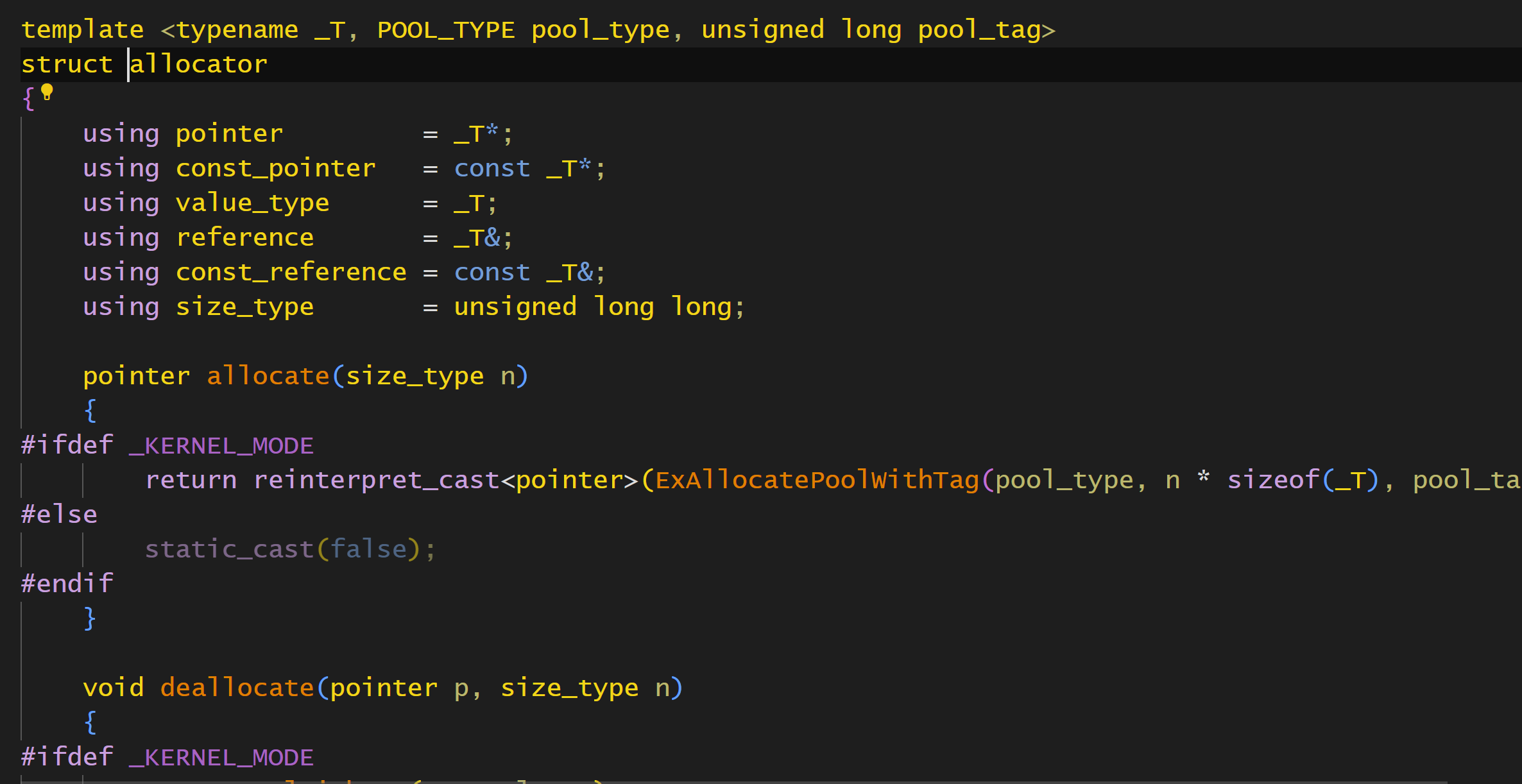
然后就是这些,必须实现allocate和deallocate,然而其实还有一些别的要实现的,比如一些获取当前内存池信息的,这里为了简单都没实现。
然后string内存还得实现一个同名的函数,这个也是stl的内容
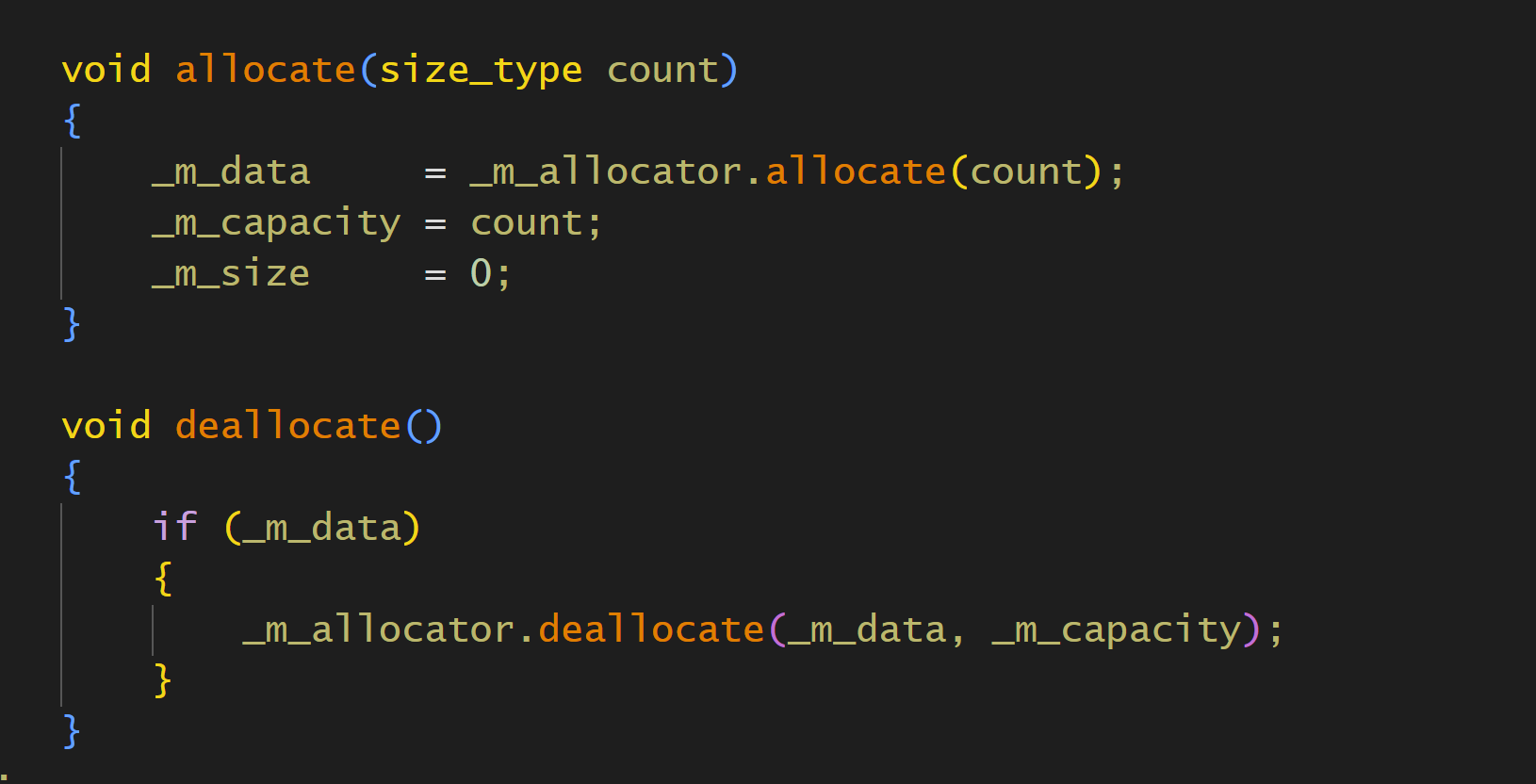
deallocate和allocate都是针对当前string的
- 为了避免抛出异常,在某些不得不返回引用的情况,可以这样写:
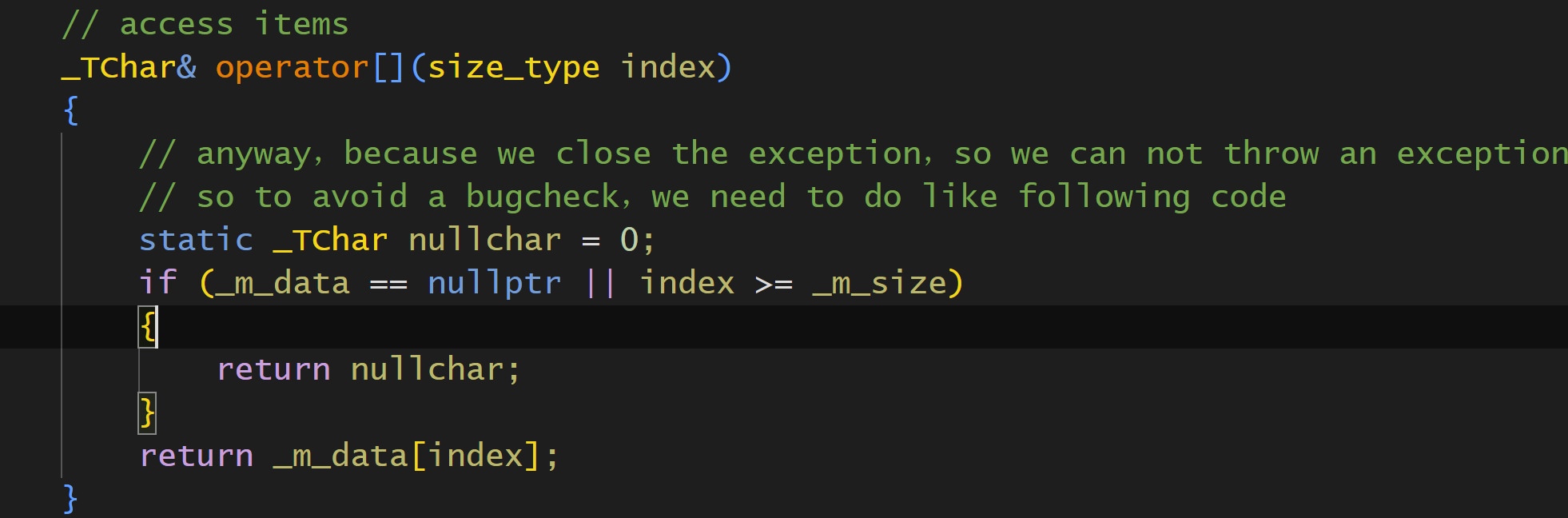
可以在函数内定义个非全局范围的static遍历来返回(PS:这里因为_TChar一定是char或者wchar,所以可以=0,但是在内核,有构造函数的类是没办法声明static的)。
capacity、length
capacity才是string的字符串指针真正的容量,而length只是字符串长度,比如resize其实改的是length,如果length==0,哪怕capacity很大,也有指针,其实字符串也算是空的。而reserve是在更改capacity。
- to_w/string
这个实现有了Cpp 17其实方便得多:
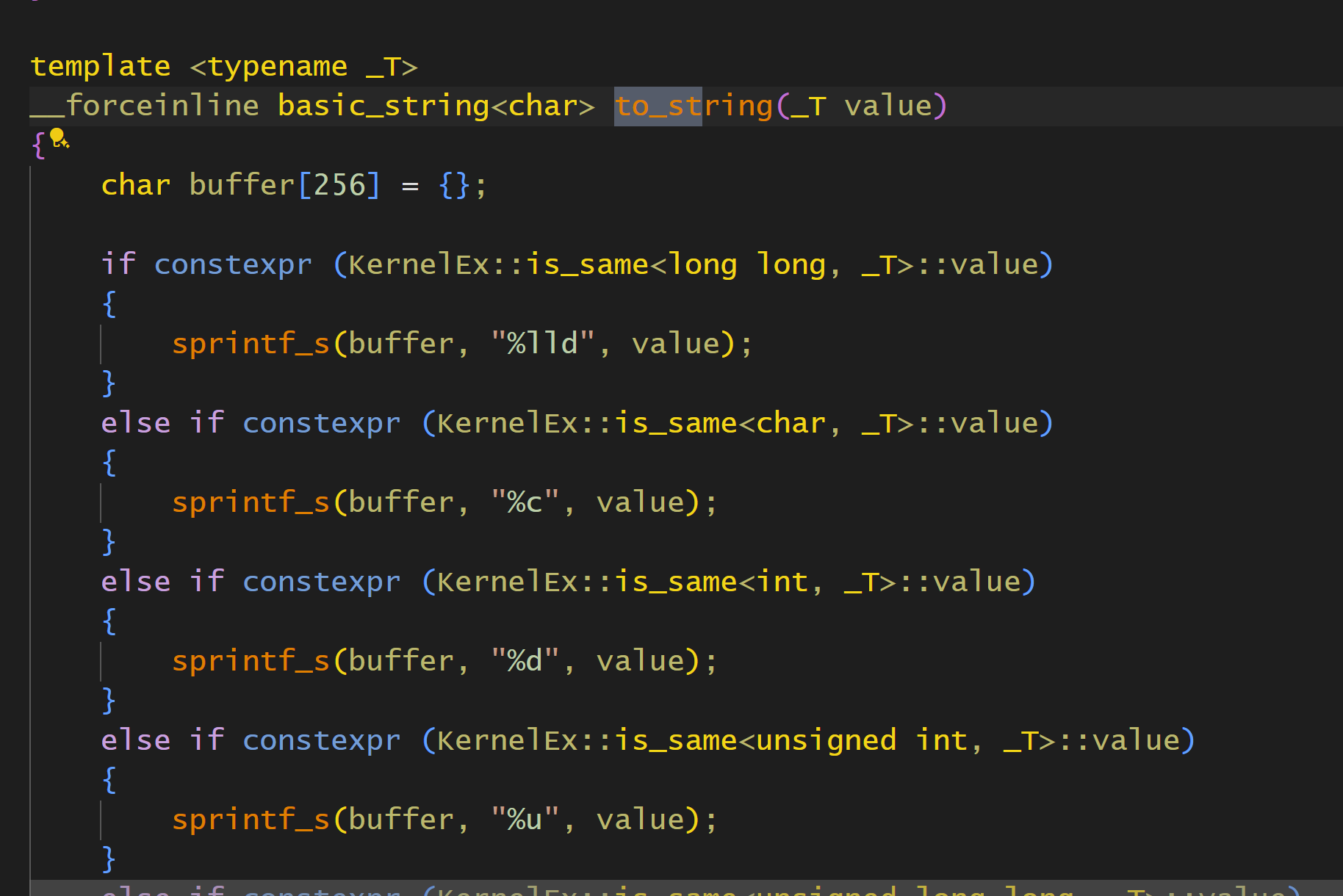
直接if constexpr即可,如果放在以前,无法constexpr,那么必须要写一堆模板特化
比如想写个int的to_string
template<>
__forceinline basic_string<char> to_string(int val)...chrono-√
chrono库不知道是C++几引入的了,没记错的话应该是C++ 17.你要说他有多实用吧,其实好像也没太有用.个人对于这个库作用总结下,就下面几大方面:
- 获取系统时间 本地时间等…
这个是通过system_clock::now先获取系统时间,然后获取到的系统时间其实不是常规意义上的几月几号纪念几日,而是一个时间间隔,这个时间间隔的单位应该是100纳秒,注意,这里不太确定.那既然是时间间隔,起始时间是多少呢,一般而言是1900年1月1日到目前的间隔以100纳秒为单位的一个数值.
而要转换成本地时间,一般会用到一些函数,会把它转成当前电脑时区的时间,然后以年月日等格式显示
注意这个地方要加1900,月份要加1,很奇怪,但是这是必须的…因为他的base时间是本地时间的1900 1 1
月份+1是因为取值是0~11

- 高精度计时时钟
其实chrono的时钟就三个,两个是计时时钟,一个高精度,一个低精度.然后就是上面提到的system_clock.
而计时器时钟一般就是用于性能测试,比如
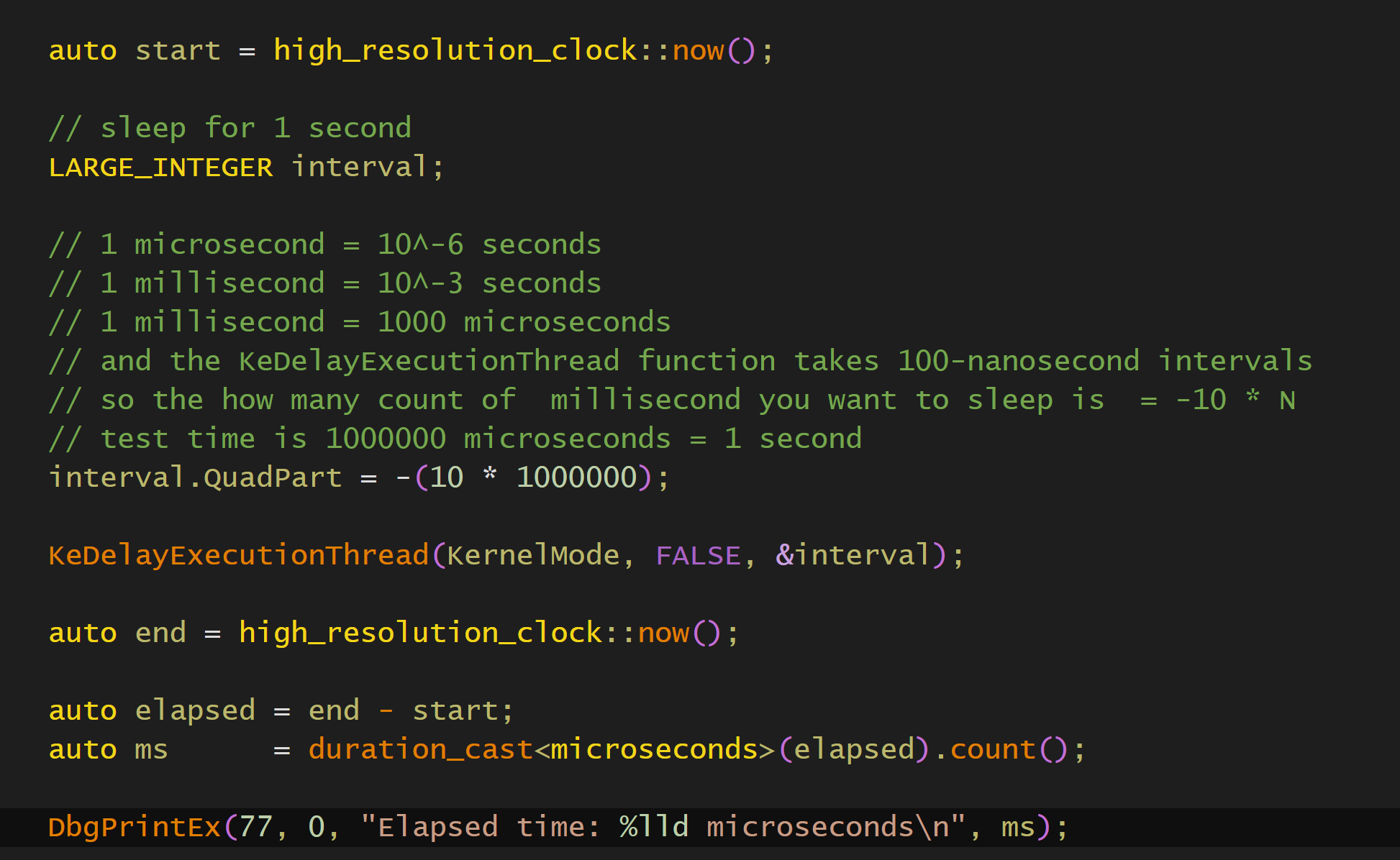
在两次now之间,sleep一次,然后去看消耗了多少时间.
- 不同时间单位之间的相互转换
简单理解就是,这个库提供了各种时间单位比如nanoseconds…等时间单位的定义,同时提供了函数进行转换.
让你可以无缝地使用duration_cast来把duration进行转换.
其实可能还和一些库进行联动,比如thread这个库,他sleep的时候,参数就可以填写一个duration.
接下来介绍chrono库到底怎么实现.
首先需要实现一个ratio,这是一个比例,用于单位转换
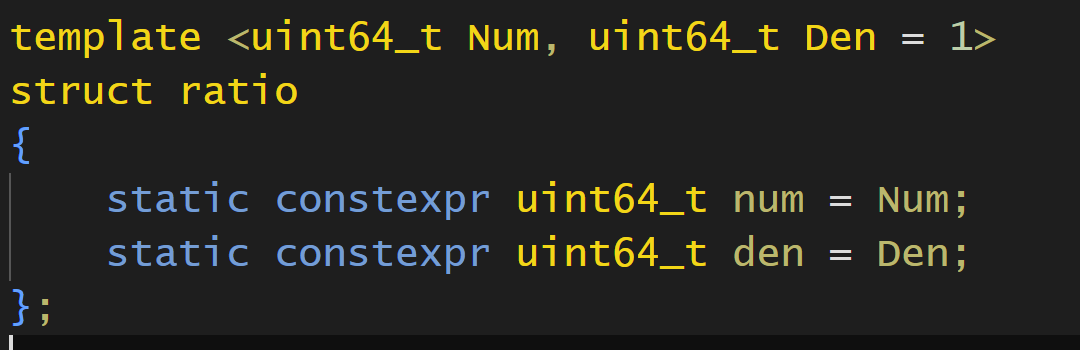
num分子,den分母.这个默认是1,我们默认的基准是秒,也就是默认比例是1:1
然后实现一个duration类,
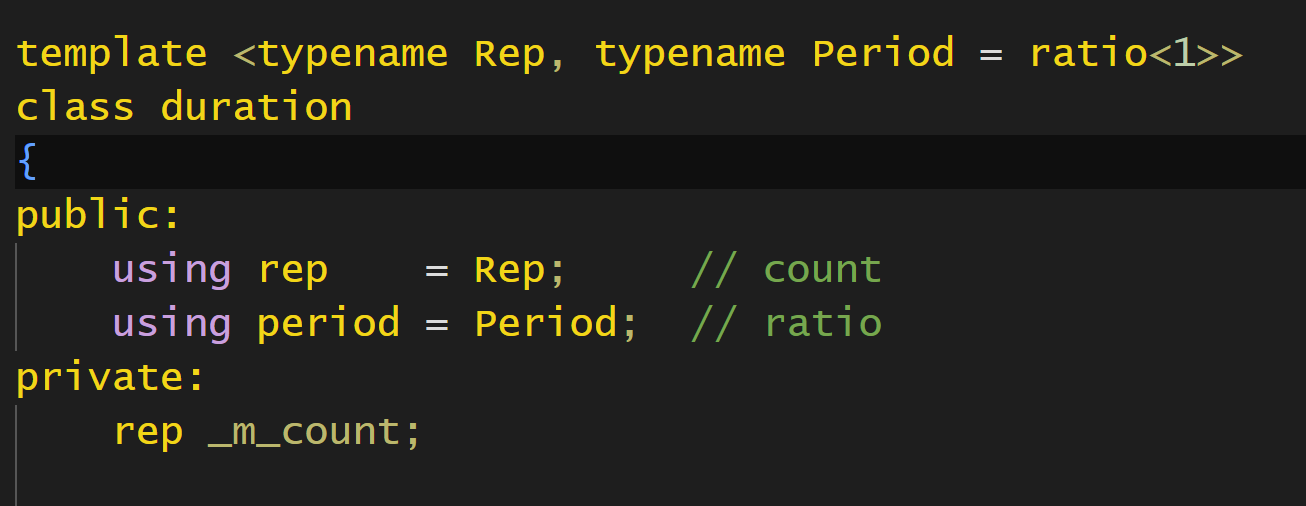
这个类就可以理解为是一个时间间隔了,Rep就是count的类型,一般都是int64,而period就可以理解为单位,count就是多少个这个单位,据此就可以表示一个时间间隔.
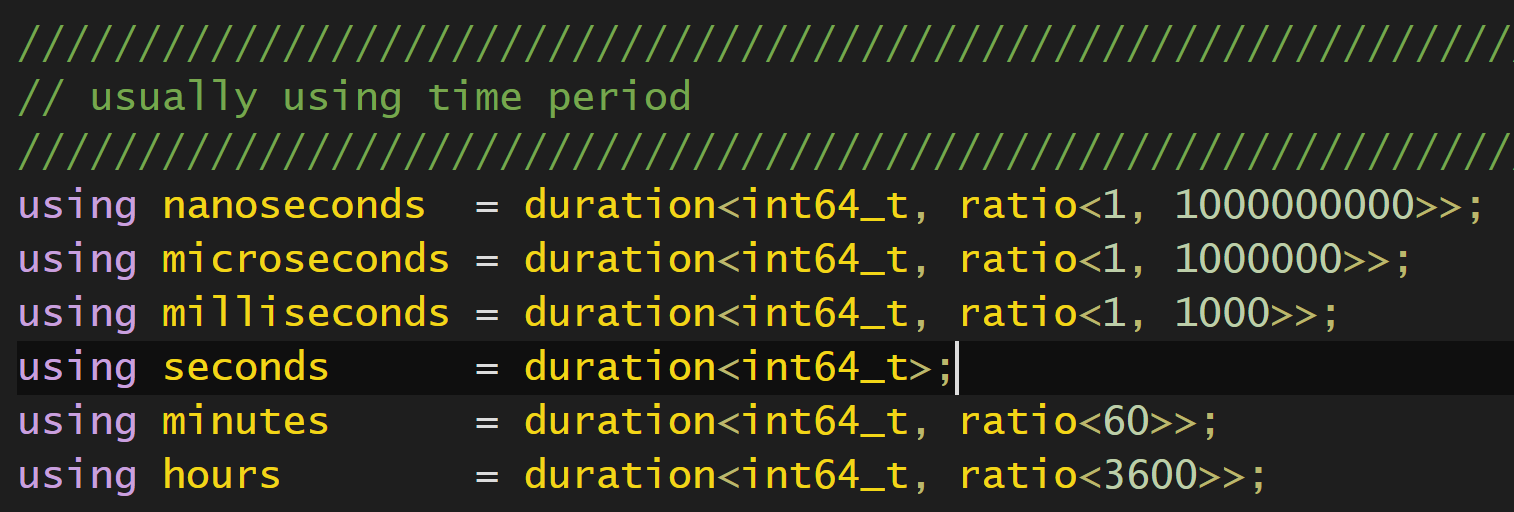
如上图,简单易懂.
接着我们可以写一个很重要的函数duration_cast,这个实现起来其实很简单,也是一个模板函数,模板参数是转换到的duration和原始的duration
然后我们现在有count(未转换的),有两个时间单位的比例,所以其实转换器来就是
原始count * (原始比例 / 要转比例)
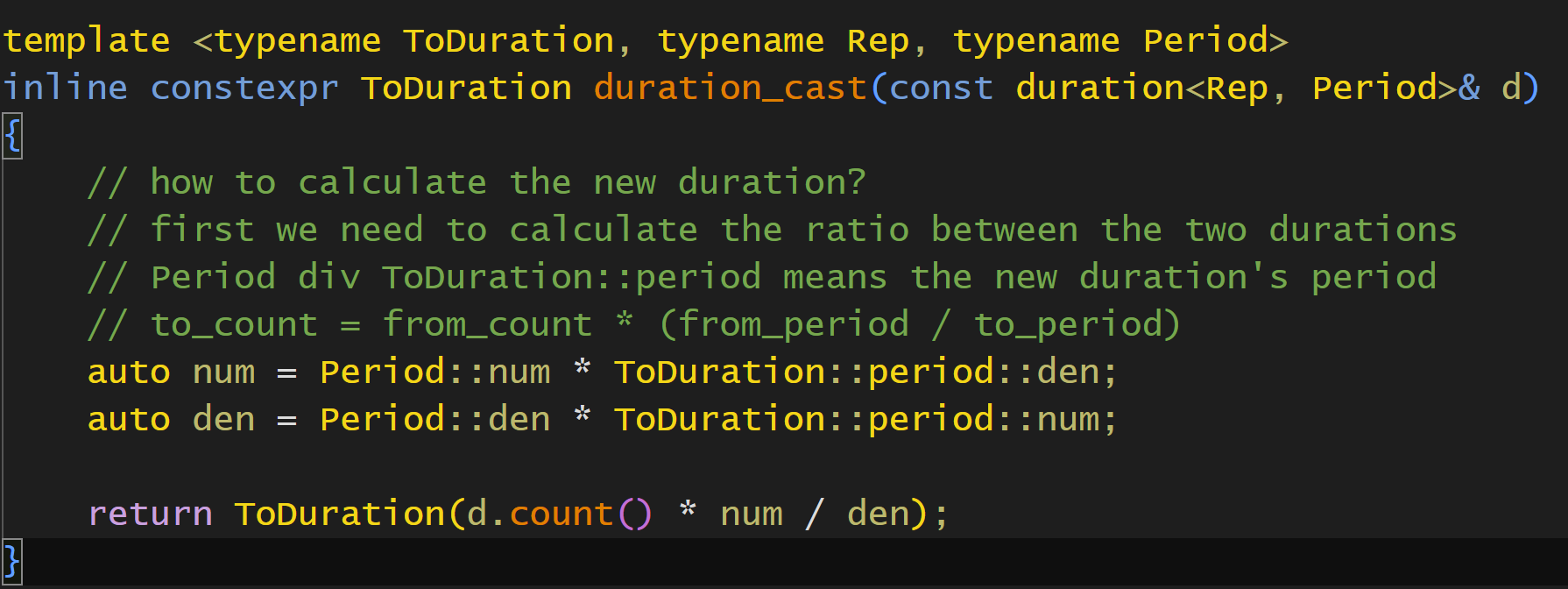
这样一个很重要的函数我们就实现了.后两个模板参数是隐式推导的,前面则是手动指定.
接着就是时间点,简单理解的话,这个时间点其实就是对于duration的一个封装,同时还封装了Clock,因为Clock是有duration的,也就是时间单位是指定的.
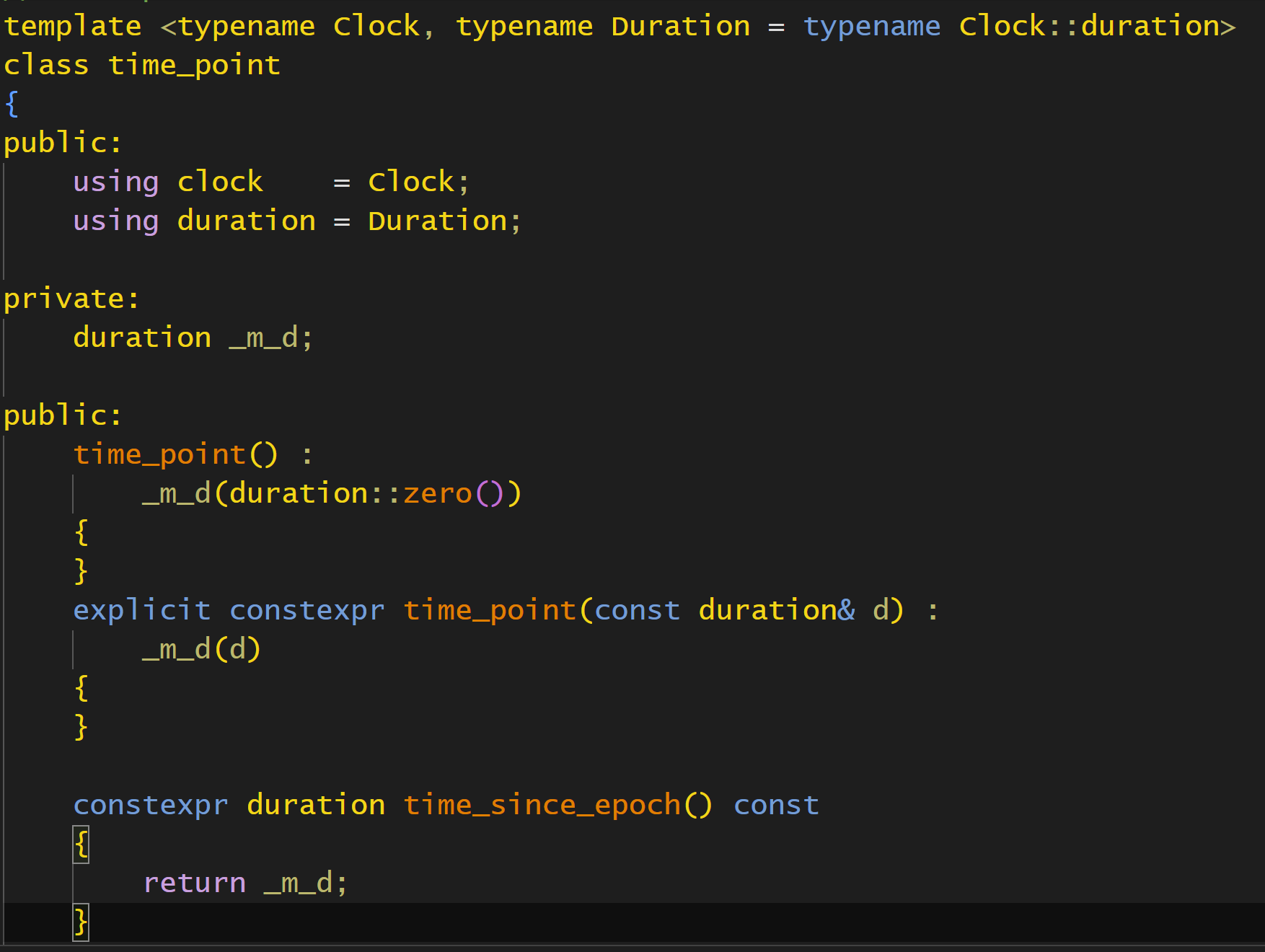
其实可以发现,这玩意完全就是封装的duration,只不过时间单位是从Clock拿的,这个time_point就是clock的::now生成的.
那么接下来就可以实现clock了,这里只写个高精度时钟怎么实现(其实这个精度一点也不高,100纳秒,stl的是纳秒!)
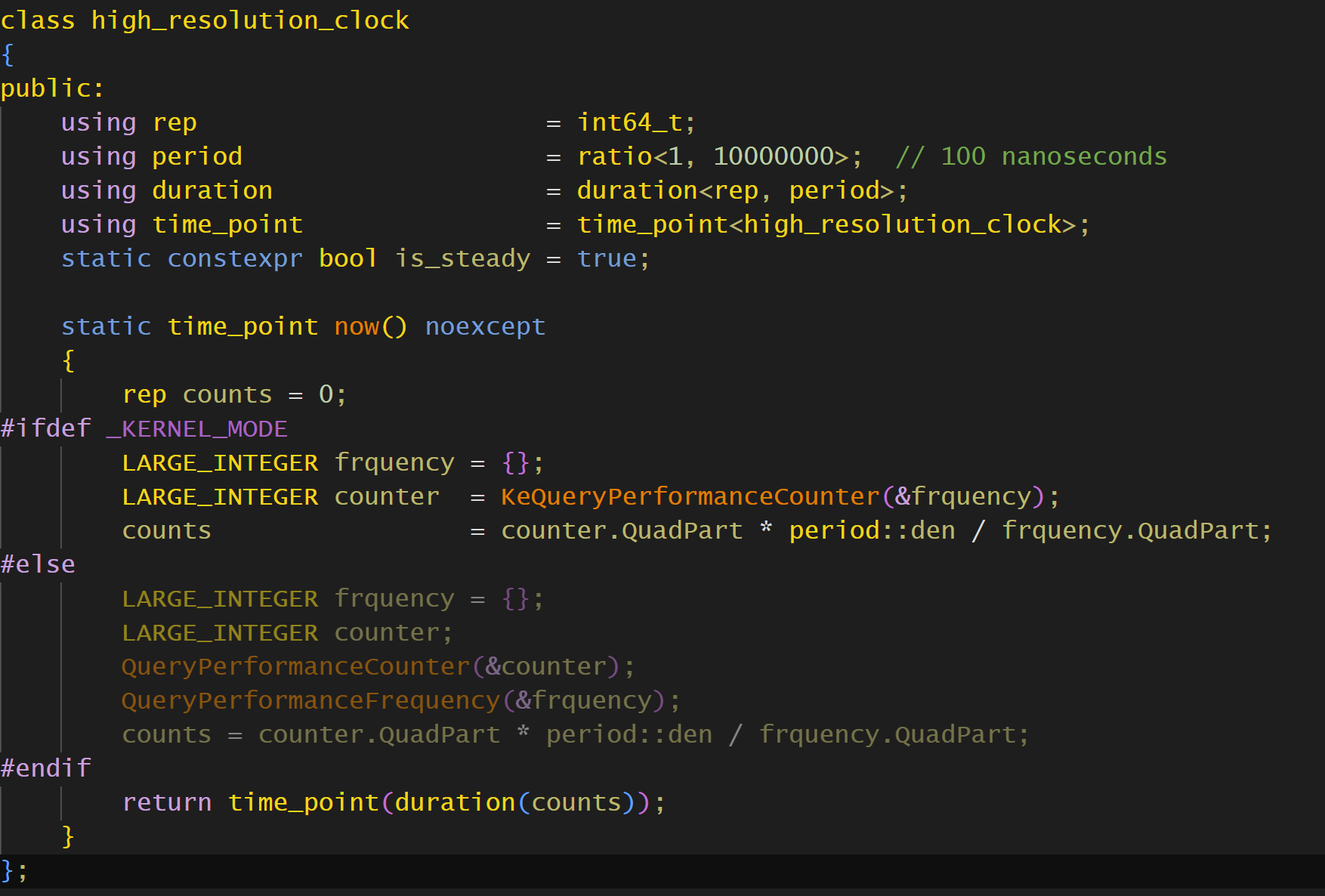
总之,实现起来很简单,想获取生成的time_point的duration只需要调用time_point::time_since_epoch
format-√
实际上,format完整实现起来贼复杂,这里可以先看下cppreference的format

fmt的里面的replacement field的组成是{arg-id(option) : format-spec}
arg-id就不赘述了,主要将这个format specification

是填充符 + <>左右对齐 + format的长度,还可以格式化浮点数
比如{:10.5f},精度5,宽度10,如果这样写,那可就太复杂了,因此我这里就实现了一个功能,就是占位符{},里面不能添加任何参数,否则不识别.
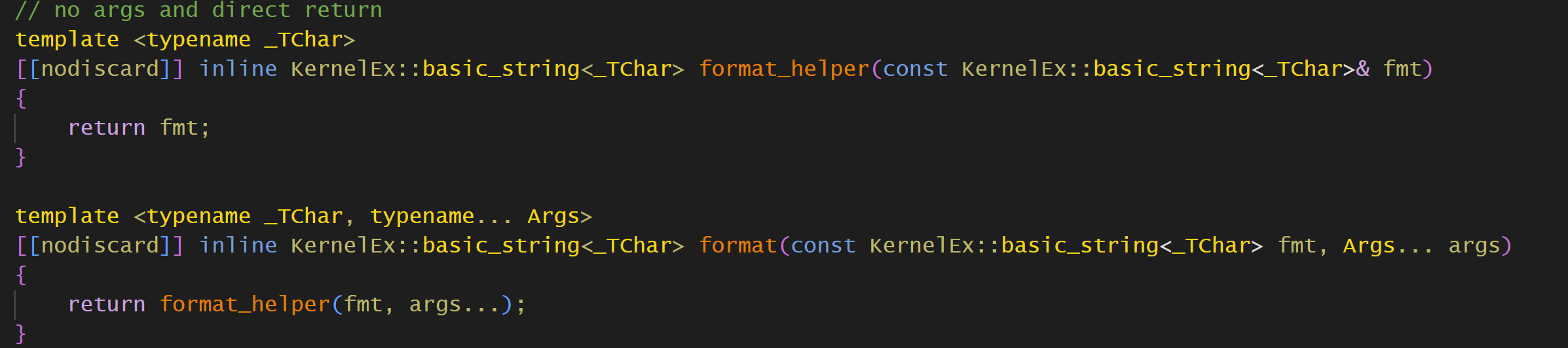
实现个format_helper,先实现个无参的,直接返回.
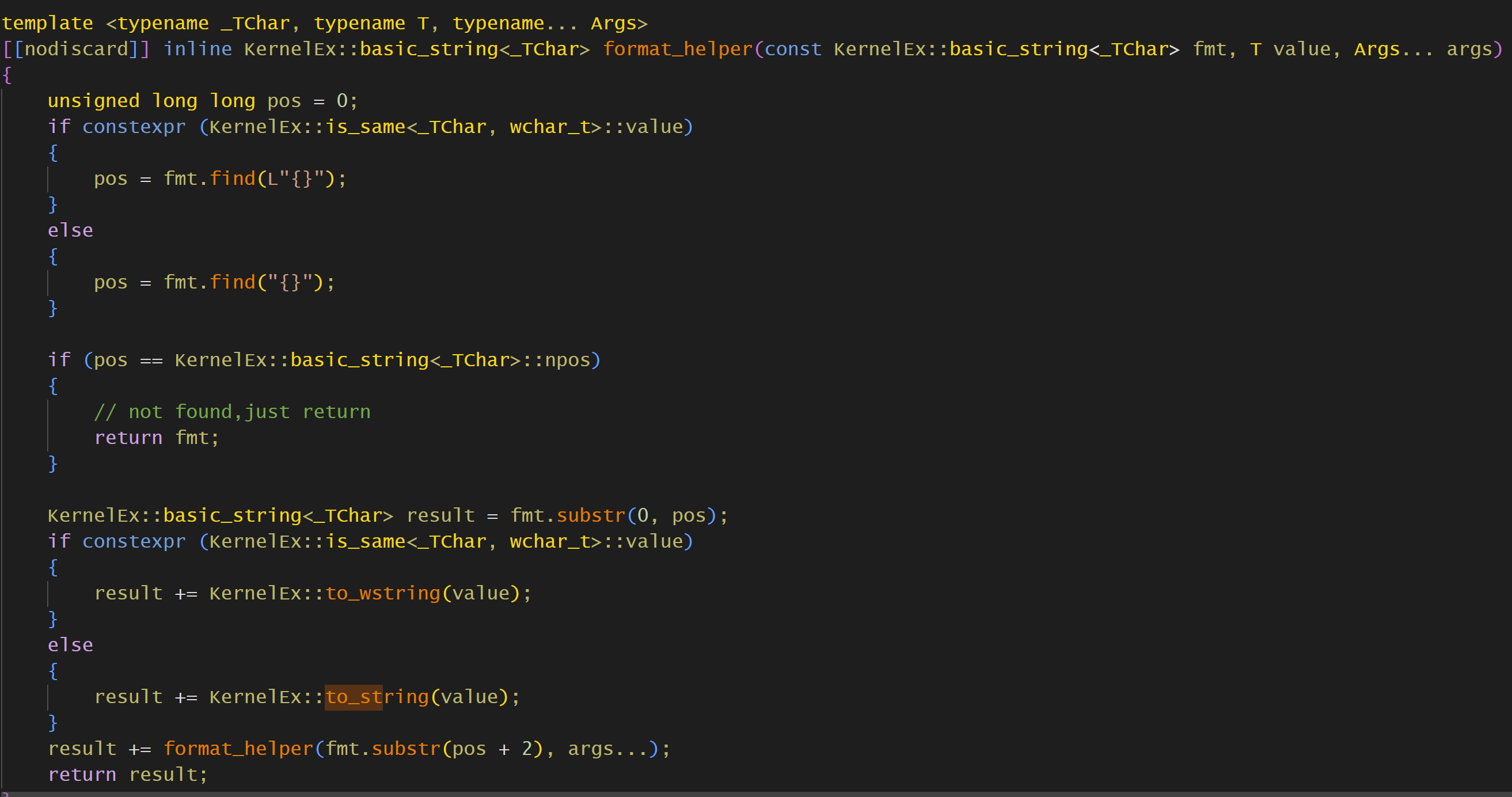
有参数的也比较简单,有参数就是3个参数,分别是fmt,然后args…展开的第一个,剩下的展开参数都继续跑到args里面
然后查找”{}”,如果有,就替换成T,总体来说就是一个模板递归,实现起来非常简单,只要to_string函数实现了对应类型的T就行.
Array
Vector
deque
list
map/set
functional
SFINAE
declval
random
atomic(cpp memory module)

atomic关系到C++的内存模型,但是严格意义上,C++是没有固定内存模型的。他能做到的就是使用某些语法可以保证你的内存序列。
首先就是atomic的基本用法,其实就是一个跨平台的原子变量+内存序列,使用模板包装,常用的函数就那些:
原子保证了使用这个变量的时候,只有一个线程会对其操作,而内存序就比较复杂了,下面会介绍。
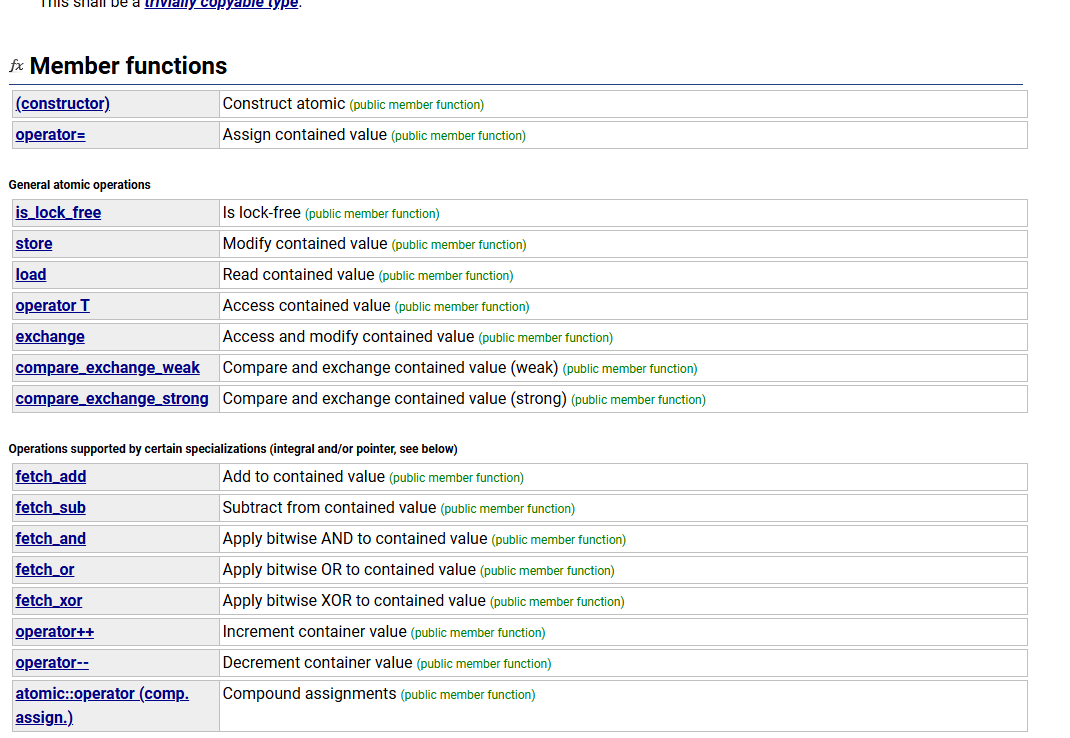
其他的都无所谓,有一个非常重要的参数,那就是内存序。几乎所有的atomic的函数带有一个默认的参数

叫做memory order,这个就是内存序参数,默认是seq_cst,这个可以认为是上下都加了内存屏障,是最严格的内存序列。比如下述伪代码
int data = 0;
atomic<bool> flag;
void thread1()
{
data = 1;
flag.store(true,xx); //
}
void thread2()
{
while(flag.load(xx) != true);
// ok,we can modify data or do something
}
void thread3()
{
execute:
thread1() & thread2()
}这个xx代表内存序列,如果是releax,那么什么都不加。理论上来说,flag.store可以先于data,而thread2的do somtthing甚至可以先于while(),这个即可能是CPU影响的,也可能是编译器去优化安排的。
而一旦使用sec_cst这个内存序列,就会告诉编译器,我在前后都插入了内存屏障,保证执行顺序。
事实上,在x86硬件平台的TSO(Total Store order)下,虽然会有乱序执行,但是最终输出的结果一定不会是乱的。也就是在x86平台,这个内存序列默认是sec_cst。但是ARM、RSIC-V,是真的会乱序执行,造成汇编不一样的,这个时候就有区别了。
而acuire和release一般就是只保证上面有内存屏障和下面有内存屏障。
总之总结下无锁编程的原子操作的规范:
- 不要使用非原子变量当作多线程的flags,这在C++是未定义行为,随时可能会被优化,参考如下代码:
int data = 0;
bool flag= false; // donot use atomic,but use a normal bool variant
void thread1()
{
data = 1;
flag(true); //
}
void thread2()
{
while(flag != true);
// ok,we can modify data or do something
}
void thread3()
{
execute:
thread1() & thread2()
}这样最后会发生什么情况呢?Debug模式下,可能会没问题。但是release会出现大问题,你会发现你的程序死循环了。
这是因为release编译器优化成了如下伪指令:
load_flags
mov eax,[flags]
cmp:
test eax,eax
je cmp
xxxx可以发现,他为了更快,把这个值放在了寄存器里面,造成了死循环。
解决这个方法就是1.对变量volatile(不推荐,本质上还是未定义行为) 2.使用atomic
- 原子变量 一个函数、一行不要出现两次。
atomic<int> a = 1; //隐式的转换成了 a.load(1)
a=5;//√
a = a + 1;//×,一行代码不要出现两次原子变量- atomic的内存序,x86可以不管。其他平台,只是自己使用,用releax。保护别人用sec_cst
algorithm
share/unique_ptr
thread
chap07 Preview syntax
chap 08 modern cpp magic
complie time string encrypt
现代C++的黑魔法有很多,其中一个就是通过模板的编译时加密字符串。而实现它,我们同样需要用到模板元编程,使用index_sequence
index_sequence
首先可以先来看看stl的index_sequence以及如何去实现它
我们在写模板的时候,经常遇到
template<typename... Args>这种模板变参,C++模板同样可以使用类型,比如
template <size_t... Indices>
struct index_sequence
{
};
这样在进行模板化的时候,参数填写index_sequence<1,2,3,4>,Indices就可以进行展开成1.2.3.4。同时,还需要实现一个make_index_sequece来进行实现一个从0-N的Indices,而这个实现稍微有点复杂,需要用到模板递归:
template <size_t N, size_t... Indices>
struct make_index_sequence : make_index_sequence<N - 1, N - 1, Indices...>
{
};
template <size_t... Indices>
struct make_index_sequence<0, Indices...> : index_sequence<Indices...>
{
};简单解释下,首先,必须我们要实例化make_index_sequence模板,
make_index_sequence<10> lala;首先他会匹配上面的版本,因为下面的特化要求N=0,我们输入的是10,显然不符合要求。那么就变成
make_index_sequence<9,9>->make_index_sequence<8,8,9>->make_index_sequence<7,7,8,9>
...
make_index_sequence<0,...9> : index_sequence<0..9>这样递归,就可以得到一个index_sequence了模板了。
这个就可以做到在编译期间进行一个数组的遍历:

比如我可以写个模板参数,接受这个类型:
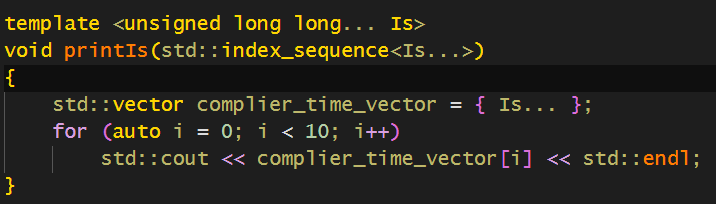
就可以完成编译时初始化:
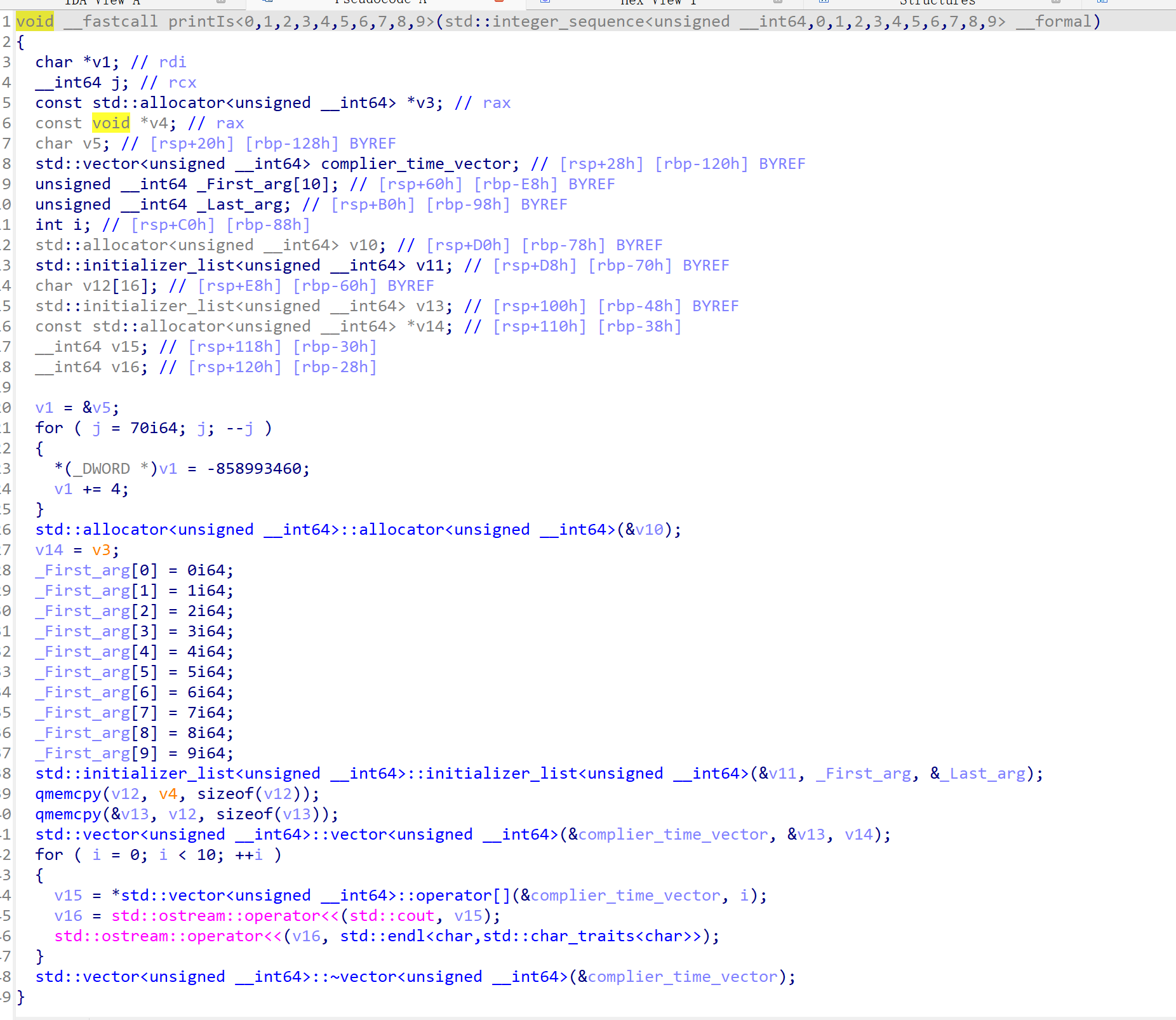
有了这个基础,我们就可以写一个简单的编译期字符串加密了
template <CompileTimeXor_size_t N, int K>
struct XorString_A
{
private:
const int _key;
mutable int _encrypted[N + 1];
constexpr int enc(int c) const
{
return c ^ _key;
}
int dec(int c) const
{
return c ^ _key;
}
public:
template <CompileTimeXor_size_t... Is>
constexpr __forceinline XorString_A(const int* str, KernelEx::index_sequence<Is...>) :
_key(RandomInt<K, 0xfffffffful>::value), _encrypted{ enc(str[Is])... }
{
}
__forceinline const char* decrypt() const
{
for (CompileTimeXor_size_t i = 0; i < N; ++i)
{
_encrypted[i] = dec(_encrypted[i]);
}
_encrypted[N] = '�';
return reinterpret_cast<char*>(_encrypted);
}
};具体而言也很简单,但是要注意的是,相关函数一定要是constexpr,decrypt和dec不要,然后定义个如下宏:
#define XORSTR_A(s) (KernelEx::XorString_A<(sizeof(s) - 1) / sizeof(int) + 1, __COUNTER__>(reinterpret_cast<const int*>(s), KernelEx::make_index_sequence<(sizeof(s) - 1) / sizeof(int) + 1>()).decrypt())注意,这里我使用的int,因为如何一个字节作为密钥,ida会直接优化,最后效果如下:
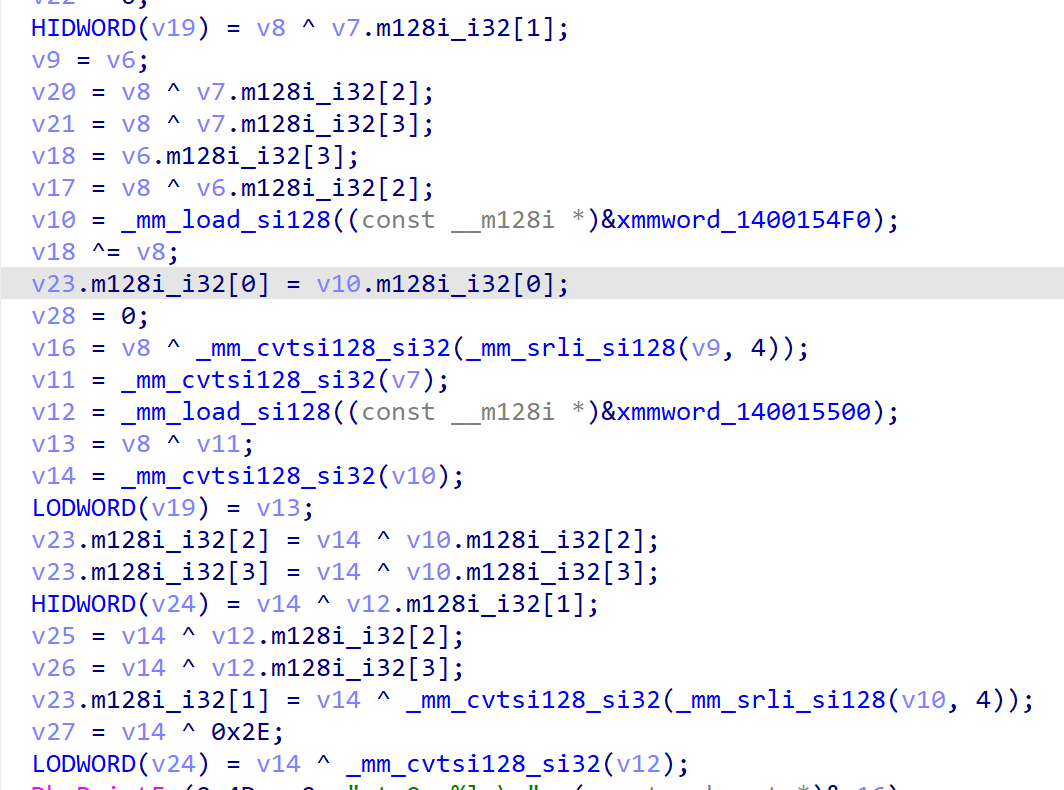
这么夸张是因为release模式下使用了一些优化,用了xmm寄存器。
Modern Cpp Logger
前面我们已经是实现了format和to_string,有了这两个工具,我们便可以施展一些小小的魔法,来实现一个非常现代的log函数。
首先,我们要实现一个log,要明白一个现代的log系统需要由什么组成。
- 严谨的日志等级
- 比如trace(最低)、debug、info、warning、error、fatal
- 同时有一个全局变量,用于规定显示出来的日志最低等级
- 可以显示当前行数、源码文件位置
- 清晰易懂的变参增加
那么我们能否不用丑陋的宏,来声明一个log,让他具备上面三种特性呢?
答案肯定是可以的,但是要施展一些small tricks,首先,清晰易懂的变参增加我们可以使用模板变参。
那么如何log的时候显示当前行数、源码文件位置而不使用宏呢?其实是可以的,我们可以使用默认参数!
比如这个类(仿照的c++的std写的,他那个是无视编译器的)
class source_location
{
private:
const char* _m_file;
int _m_line;
const char* _m_func;
constexpr source_location(const char* file, int line, const char* func) noexcept
:
_m_file(file), _m_line(line), _m_func(func)
{
}
public:
static constexpr source_location current(
const char* file = KERNELEX_FILE,
int line = KERNELEX_LINE,
const char* func = KERNELEX_FUNCTION) noexcept
{
return source_location(file, line, func);
}
constexpr const char* file_name() const noexcept
{
return _m_file;
}
constexpr int line() const noexcept
{
return _m_line;
}
constexpr const char* function_name() const noexcept
{
return _m_func;
}
};这样,我们在实例化的时候,对source_location使用current默认参数,就可以正确地获取当前信息:
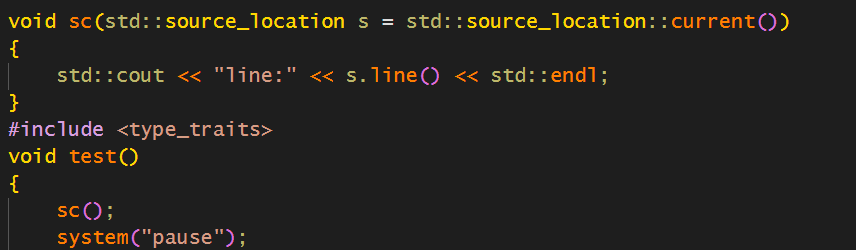

但是,还是有个问题,那就是如果使用模板变参,那么前一个或者后面参数都不能再用默认值了。这个话可能比较拗口,但是代码如下:
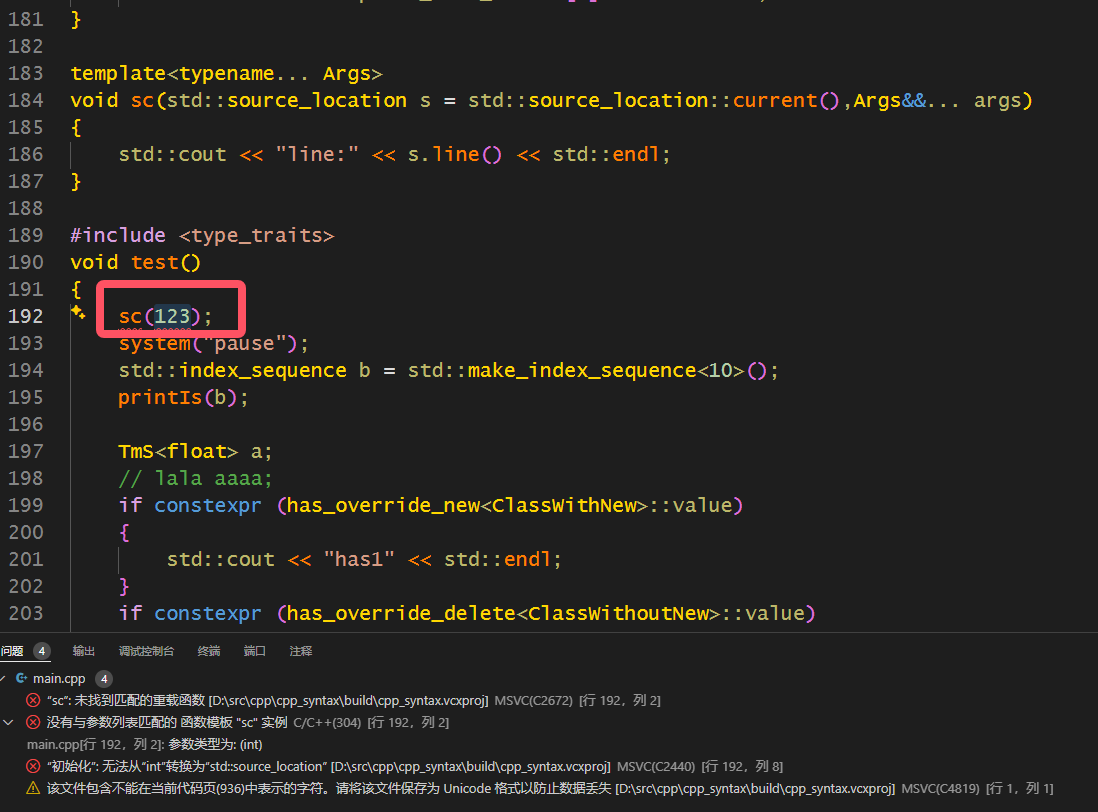
这也就代表着,我们还是必须显示地写source_location::current,这是我们不希望看到的。因此这里用到了一个技术来进行包装。
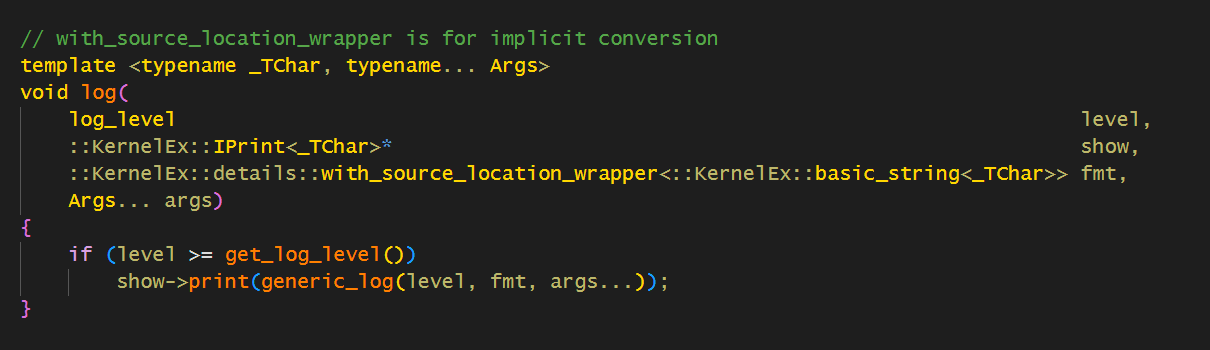
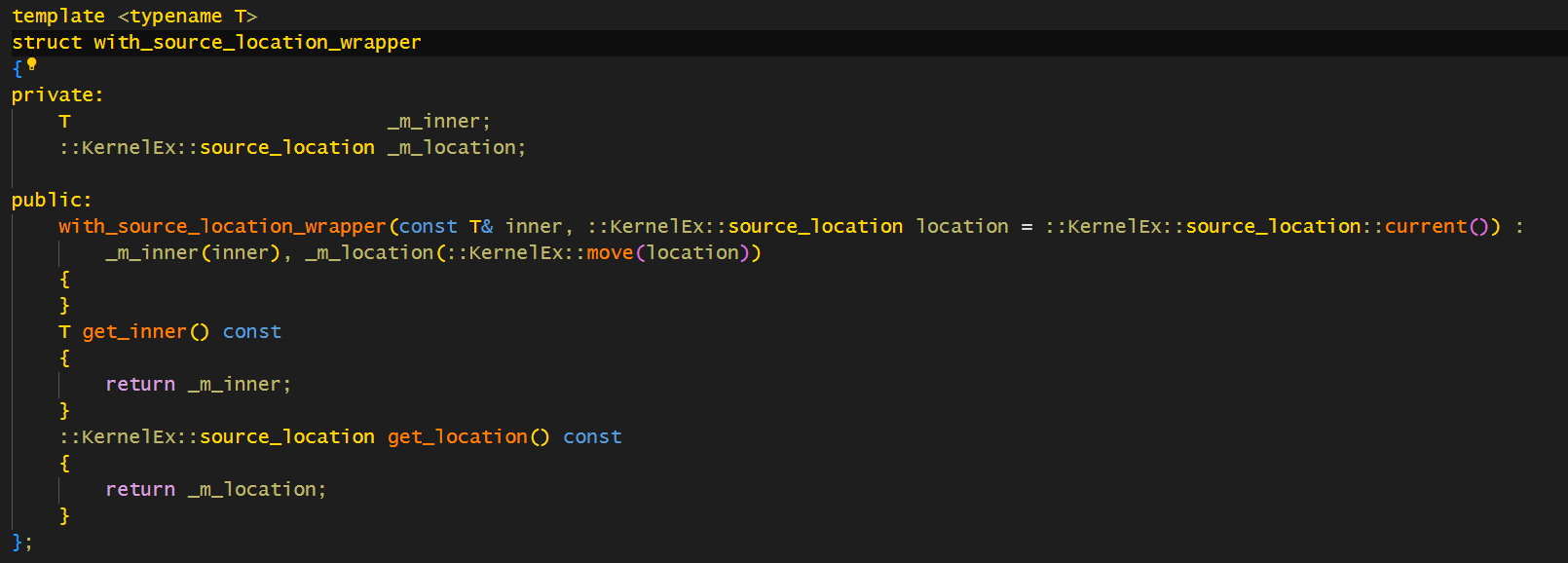
这样包装,需要填写参数的时候,将basic_string隐式地转换成这个with_source_location,所以构造函数一定不能声明explicit。
而至于log本身,其实非常简单啦:
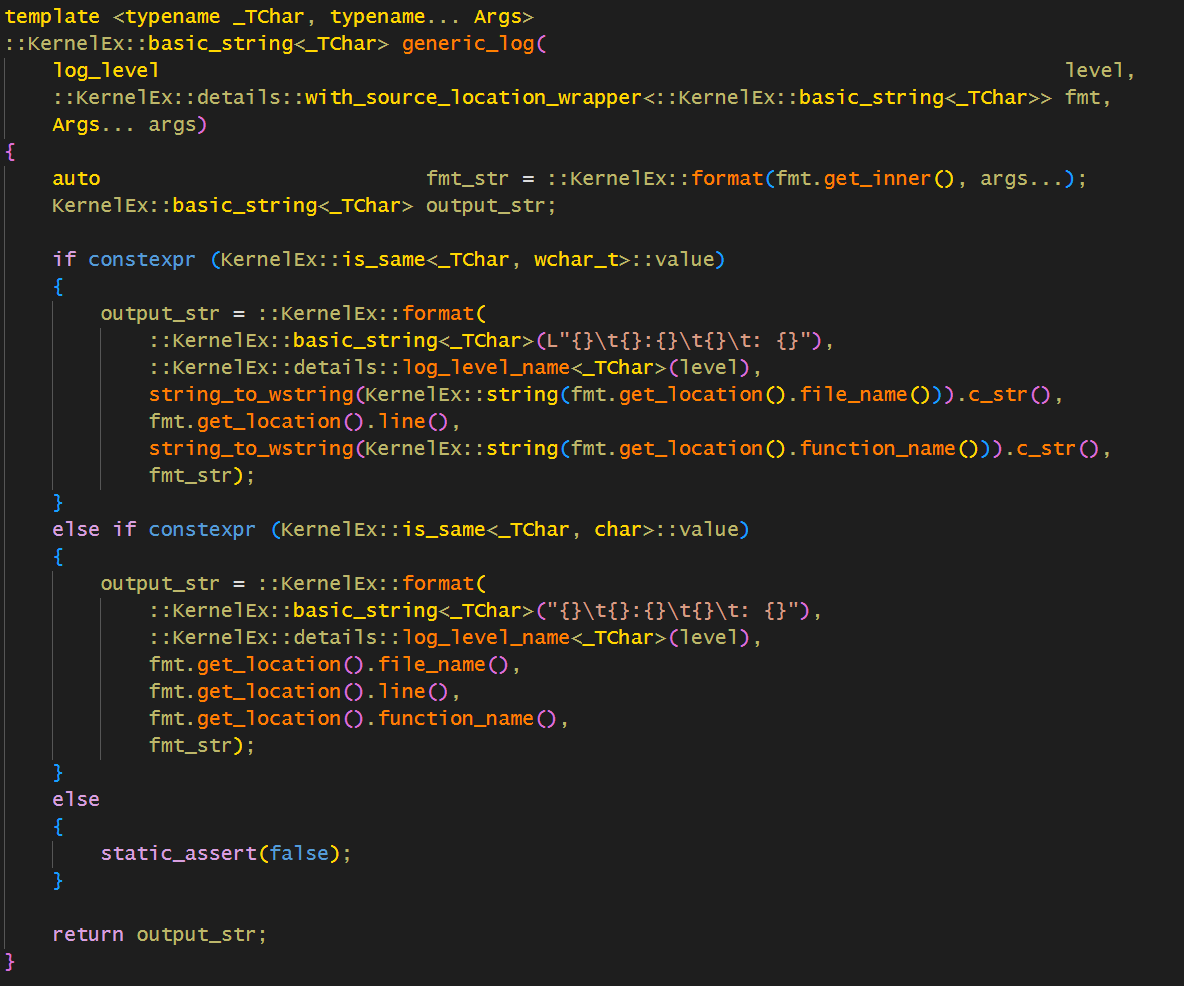
最后可以打成如下效果:

X-Macro
前面提到了,一个log有很多日志等级。但是一旦设置到这种,我们就要写很多代码,比如switch,来进行各种兼容。
那么有没有一种方法,可以牵一发而动全身,修改一个地方,定义的所有都会改变呢?
答案是肯定的,这种技术就是基于宏的X-Macro技术。
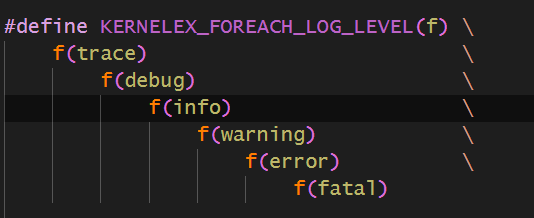
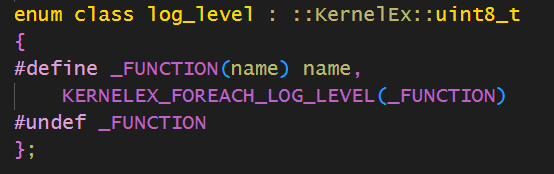
这个意思是,定义一个宏,宏接受一个宏函数,然后就会将下面这几个参数以此传入这个函数宏,比如我们想要定义枚举:
再比如我们想要定义switch case
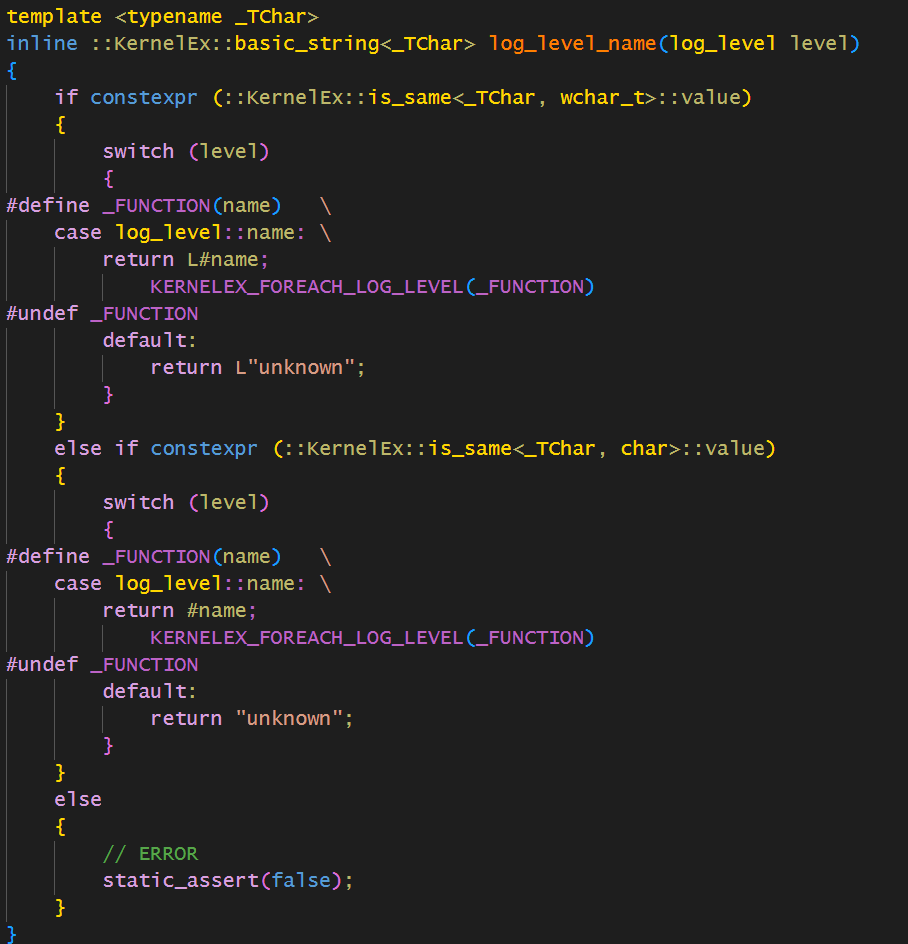
这个还是很优雅的!
XX Guard
Scope Guard
这个可以实现,在函数结束肯定能保证Scope Guard里面的东西会被执行
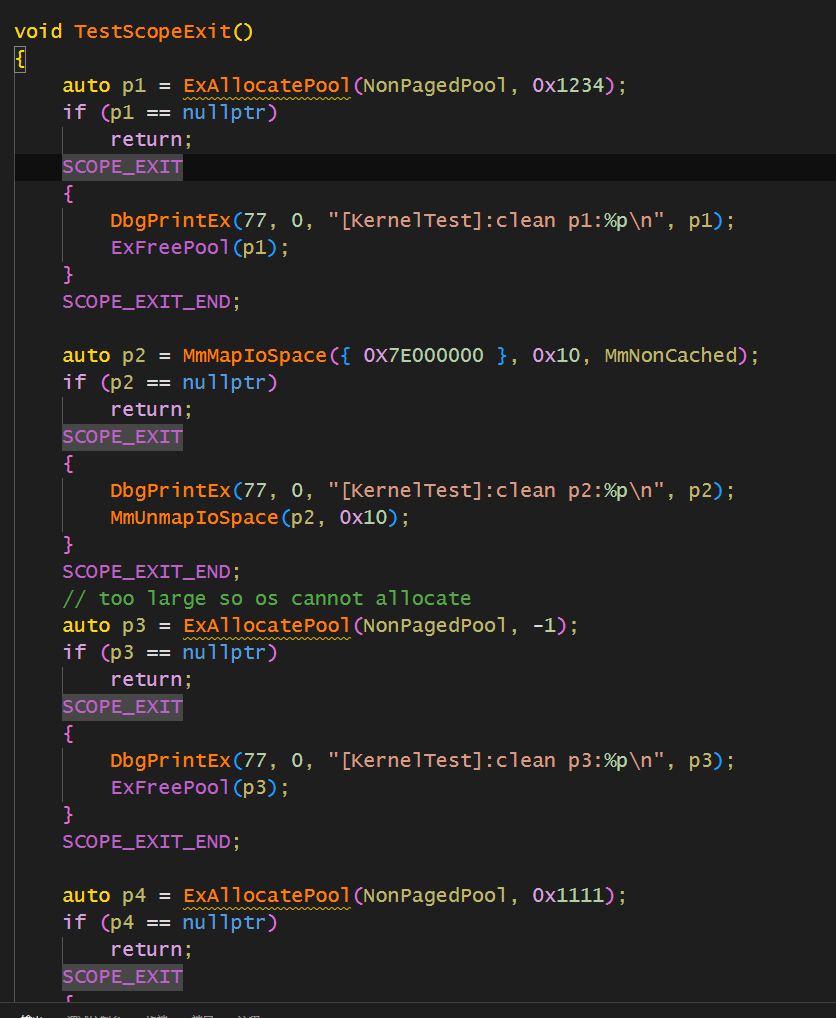
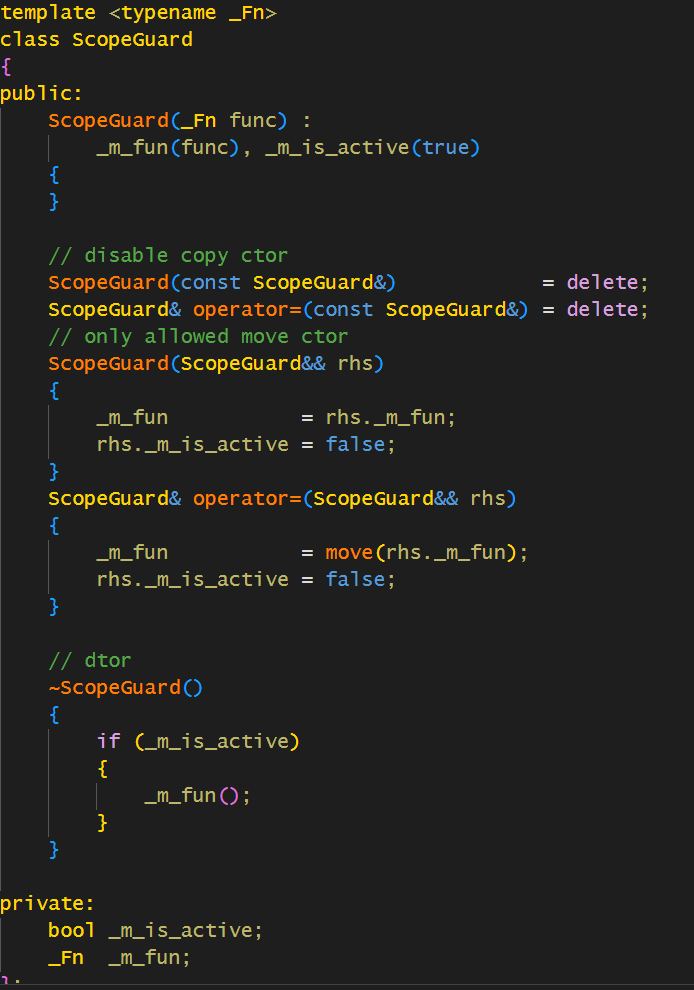
其实这个实现就用到了RAII,SCOPE_EXIT其实本质上就声明了一个根据行不同名字的,因为可以捕获以前的参数,所有用到了lambda

MakeScopeGuard返回一个如下类,而这个类只有在析构的时候执行相关函数。

https://shorturl.fm/NtyF2
https://shorturl.fm/m6Nza
https://shorturl.fm/J7rQE
https://shorturl.fm/0pM0w
https://shorturl.fm/L3kvf
https://shorturl.fm/pncvI
Earn passive income this month—become an affiliate partner and get paid!